

Journal reference: Computer Networks and ISDN Systems, Volume 28, issues 7–11, p. 1053.
Exorcising daemons: A modular and lightweight approach to deploying applications on the Web
Jonathan Trevor, Richard Bentley and Gerrit Wildgruber Abstract
The World Wide Web (W3) is increasingly been seen as a platform for enabling remote access to new and existing applications from different client machines. While some applications have been deployed through specialised, proprietary W3 servers, the majority utilise the CGI interface provided by standard servers to provide all application functionality external to the server itself. Using experience gained in developing the BSCW Shared Workspace system, we argue that this `API-based' approach is both too restrictive and too `heavyweight' for the needs of many applications, which often require a small subset (or a different implementation) of the features the server offers. In contrast, we propose a more modular, component-based approach to enable applications for the World Wide Web, and present a prototype implementation of an integration toolkit which demonstrates this. As well as the potential for greater flexibility, performance and smaller application size, this approach also naturally extends to other methods of access and interaction such as electronic mail. Introduction
The World Wide Web (W3) has rapidly become the primary means of accessing information over the Internet and continues to grow unchecked. According to Lycos, by September last year more than 8 million documents containing nearly 11 million URLs were accessible over the Web [1]. The majority of this vast quantity of information is however served by a relatively small number of different W3 server applications, or daemons, with a recent survey highlighting NCSA's httpd (28%), Apache--an NCSA variant--(27%), Netscape's Commerce and Communication servers (17%) and CERN's httpd (8.5%) [2]. The features offered and the basic design of these servers does not differ greatly--for example, most provide facilities for authentication, access control, logging, directory listing, MIME-type mapping and so on. Much of the effort in recent releases seems to have focused on improving basic server performance (using techniques such as `process pools') rather than major changes in this behaviour and functionality. It is safe to say that current designs are highly successful for serving documents and HTML pages, and that server performance is not likely to limit the scaleability of W3 to even more users, at least for access to this type of information. Deploying Applications on the Web
Most W3 servers provide one or more APIs for integrating new and existing applications. The most well known of these APIs is the Common Gateway Interface (CGI), and although some servers (such as Netsite for example) additionally provide a specialised API, CGI version 1.1 [5] is currently standardised and supported by all major W3 servers.finger command, or an interface to a complex application such as a DBMS. Figure 1 shows this most basic interaction between client, server, and CGI script.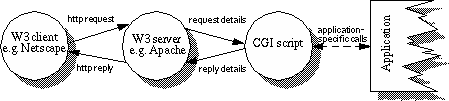
Figure 1. Application integration via the CGI Deploying a new application: The BSCW Shared Workspace system
The BSCW Shared Workspace system provides basic facilities to support collaborative sharing of information, activity awareness and integration of external applications across Macintosh, PC and Unix platforms. It supports document storage, retrieval and more sophisticated document- and user-management facilities, all of which are accessible using an unmodified W3 client such as Netscape. An early version of the system is described in [4].
Here the W3 interface acts as a simple `glue' between an existing W3 daemon and the API of the LinkWorks system which provides full authentication and access control features. Initially it was hoped that the authentication mechanisms provided by W3 servers would be useful for obtaining a user-name and password to deliver to LinkWorks (as it requires) along with details of the request, and thus provide a simple mechanism which required users to authenticate only once per session. However, although it was possible to set up the request-handling CGI scripts so that users had to authenticate with user-names and passwords, the CGI environment in which the scripts execute does not include the password supplied by the user. It was therefore extremely difficult to handle authentication for the LinkWorks system using the features provided by the W3 server, and the final solution involved developing a special `login form' and mechanisms to record authentication details and handle session management so the user did not have to authenticate with every request.
Providing a specialised daemon may be necessary to achieve adequate performance, security and so on, and allows tailoring of the services provided by the daemon to the application and removal of unnecessary services--such as directory listing, perhaps. This is possible by adapting an existing server or developing a completely new daemon, both of which are non-trivial; the former requires access to server source code which is often undocumented, while the latter requires re-coding much of the standard server behaviour and performance optimisations. Whichever method is chosen the result is a specialised daemon that must be installed and maintained separately of any existing W3 server. For some large, complex applications such as BASISplus [3], the requirements of the application may make a specialised daemon the only option, and the extra effort for development and maintenance is relatively small and acceptable. For many applications, however, this is not the case.
On the other hand, as we have shown in the examples above, deployment using CGI may cause problems when existing server features are unsuitable for an application's requirements. The result is often a need to duplicate aspects of server functionality in CGI scripts in order to achieve only minor modifications as the CGI does not support tailoring of server features. Further, developers must still be careful not to make assumptions about aspects of server behaviour such as the naming and format of log files, access control files and so on which are not standardised between servers. Generally application deployment with CGI means a greater application footprint as the server provides many features that the application may not require, and a performance hit over an application-specific daemon. It does however remove the need to handle network connections, HTTP request/reply parsing and so on from the developer, and allows installation using a standard daemon--possibly one already set up at the host site.
It might be argued that many of these problems are specific only to the current CGI standard and are not shared by other server APIs. Servers such as Netsite and Apache provide comprehensive APIs that give the developer much more control over the internal behaviour of the daemon, and thus allow more flexibility in tailoring it to the requirements of an individual application. However these APIs are currently non-standard, and applications which make use of them are tied to specific servers and versions of those servers--upgrading to a new version may require corresponding updates to the applications themselves, and older versions of the server required by the application may become unavailable. In some cases where servers are not public-domain (as with Netsite), distributing a free application which uses the API may require the user to buy a server.
It may be possible to extend CGI, or another standardised API, to provide much more flexibility to developers to enable applications for the Web in a server-independent manner. It is our belief, however, that there are a number of problems with the server API approach per se for deploying applications on the Web:
It should be noted at this point that these claims can generally be applied to W3 servers themselves, which in some sense are only special purpose applications enabled to serve documents and HTML pages using HTTP (though in practice the coupling is of course much tighter than this!). This is exemplified in the design of the Spinner W3 server [8] which is radically different to almost all other HTTP daemons. A Spinner server consists of a number of different modules, each of which handles some aspect of server behaviour and can be replaced or omitted in a functioning installation. This means that a Spinner daemon is as large and complicated or as small and simple as required, and modifying the behaviour of any aspect only requires replacing the corresponding module with a customised version. Support for CGI and modules for all standard server operations mean that Spinner can be deployed as a replacement for more conventional servers, and an efficient, multi-threaded implementation provides good performance.
For general application deployment, however, Spinner is still too restrictive. Modules have to be placed in one of eight categories, and these categories are targeted towards the features provided by a traditional W3 server. In addition, modules have to be coded in an (as yet) obscure and poorly documented language called uLPC. A related but more flexible approach is to embed support for arbitrary extension modules within the server, possibly written in different languages. This is being attempted by a group at Digital Creations [7] who have embedded support for the ILU distributed, cross-language programming system [9] in the Apache and Netscape servers. Although many of the problems with extending an existing daemon as described above still apply, this approach has great potential for enabling a wide variety of applications on the Web. It is however `heavyweight' as the ILU programming system is both large and complex, and many applications will not require the support for distributed execution.
We have attempted to combine aspects of both the Spinner and embedded-ILU approaches to develop a toolkit for enabling applications for the Web in a modular fashion, like Spinner, while providing the flexibility of the embedded-ILU approach in a more `lightweight' manner. As a starting point, we have isolated the following requirements as common to all such applications, and which should be supported directly by the toolkit:
1. accepting HTTP requests from W3 clients
2. forwarding request details to application specific modules
3. allowing those modules to request user authentication
4. returning an application-supplied reply to the W3 client
We have therefore designed toolkit components to support these requirements, the core of which is an Integration Service through which applications can register, receive request information and send their responses.
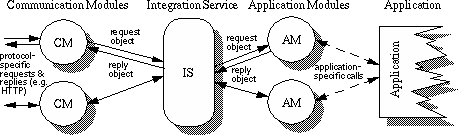
The Communication Modules (CMs) are responsible for receiving requests and sending replies from a client in a particular protocol or format. They may be small server processes, such as a minimal HTTP daemon, or programs which can be initiated from the command line, or by other servers and applications. A CM defines a mapping between the specific request format and a request object--a representation of the request which holds request details as attribute-value pairs. A HTTP request would therefore be mapped to an object which included fields like REQUEST-METHOD, CONTENT-TYPE and so on. CMs must verify the request, according to the definition of the protocol, and forward the request object to the Integration Service.
The Integration Service (IS) forms the heart of the toolkit, routing request objects to suitable Application Modules (AMs). The request object is passed on unmodified giving the AMs access to all the information supplied in the original request. The recipient AM is determined based on a table of the AMs' registered interests, defined in a configuration file by the developer and parsed by the IS on initialisation (Figure 3). The IS can be signalled to re-read this configuration file, allowing developers to modify AM interest information at run-time.
HTTP_CM: (simple_http, initialise, bscw.gmd.de, 80)
(bscw_http, handle_request, [HTTP_CM], {`URL': `^\/bscw\/?'})
(bscw_http, get_icon, [HTTP_CM], {`URL': `^\/icons\/?'})
Figure 3. Basic interest-configuration for the HTTP IS to AM mappingThe interest configuration file has two parts separated by a blank line; a header part which specifies the Communication Modules to be initialised, and the body which describes the mapping from requests to calls to Application Modules. Each entry in the header specifies the name of a CM to register with the system and about which interest information may be provided. If any parameters are given the IS will invoke the named module and initialisation method and pass the specified initialisation parameters (represented as strings). In the example above the CM simple_http will be initialised with a function call of the form:
simple_http.initialise(`bscw.gmd.de', `80')The CM will then initialise--in this case starting up a server process to listen for HTTP connections at bscw.gmd.de:80. It is expected to handle any errors on initialisation itself--for example, if the IS is being signalled to re-parse its configuration file and the server is already running on port 80. (To re-start the CM itself it is necessary to kill the CM process and either signal the IS to re-parse its configuration file or start the CM by hand from the command line).
Details of the linkage between requests, formatted as request objects by a CM, and calls to specific Application Modules are specified in the body as mappings between AM handler functions and regular expressions. These take a similar format to the CM descriptions with the name of the module and function to invoke when the IS matches a request object with a regular expression--the request object is usually the only parameter which is passed in this function call. From the configuration above requests to the simple_http CM, where the request URL takes the form */bscw/* (`*' is a wildcard), result in the following AM invocation:
bscw_http.handle_request(aRequestObject)
Evaluating the configuration file from top to bottom, the IS attempts to pattern match request objects with each regular expression, and if a match is obtained the associated AM handler function will be invoked. It is therefore possible for more than one AM to be invoked for the same request, in which case the output from the first AM is passed on an optional second parameter to the subsequent AM. In practice, we have found that this is rarely needed, as AMs can be defined which perform the coordination themselves; however one particularly useful technique for which we have used this mechanism is to re-parse the HTML output from AMs, transparently to the AMs themselves, by passing the output and original request to an HTML formatting module. This module uses details of the W3 client found in the request object, in association with a table of client capabilities, to ensure the HTML returned can be interpreted correctly--for example, substituting preformatted text for an HTML 3.0 table. Further uses might include encoding of output, automatic logging and so on.
The AMs implement the linkages to the applications themselves. Typical AMs might implement a simple routine, invoke an application using a command line call, or provide a simple client for a database server; the developer can choose the most appropriate implementation and has the full details of the request available. Should authentication be required the AM can detect the absence of authentication information in the request object and return a request for authentication which is forwarded to the CM by the IS. The CM will then request authentication from the client and forward the authentication information to the AM.
It is possible to register multiple interests for an AM with the IS allowing AMs to handle different kinds of requests. This approach also allows multiple applications to be registered with the same IS by defining AMs to provide the request-application mapping. To add or remove an AM requires only modification of the IS configuration file and signalling the IS to re-read the interest information. In addition to the IS we have implemented a number of simple CM toolkit components as well as more general routines--for example, components for basic authentication, access control, directory listing and so on which have allowed us to construct a simple W3 server using our toolkit.
The toolkit has been implemented entirely in Python. Although this greatly simplifies the problems of invoking and calling functions from CMs and AMs it would be possible to modify the interfaces between these components so that parameters were passed as environment variables or on a stream in a similar manner to CGI. Another option would be to integrate the ILU system to allow function calls to AMs written in different languages and possibly located on remote machines; as an ILU binding is available for Python, this would allow access from the Python IS to AMs written in C, C++ or Modula 3 (and further language bindings are currently being developed).
bscw_http AM. This then extracts the necessary details, such as action to be performed, and invokes the relevant function in the BSCW core, passing the request object and a flag to indicate that an HTML response is required. The BSCW system returns a page of HTML to the AM which is forwarded to the client via the HTTP CM.In our implementation of the HTTP CM, all parameters for a GET or POST request are parsed into attribute-value pairs and stored in the request object. Further information such as PATH_INFO is also stored in this manner. For example, the following URL:
http://bscw.gmd.de/a_workspace/a_folder/?op=show
(which requests the operation to generate a listing of the contents of a BSCW workspace folder) would be represented in the request object as:
`REQUEST_METHOD': `GET'`PATH_INFO': `/a_workspace/a_folder/' `OP': `show' (plus a number of other object attributes).
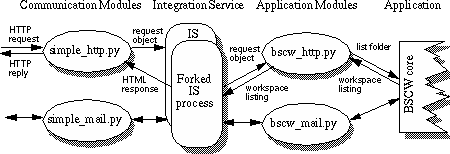
As shown in Figure 4 we have also used the toolkit to enable access to the BSCW system from electronic mail. This required writing a CM which was executed on receipt of a BSCW-specific mail message. Such email was delivered using a Unix
.forward file, and the job of the CM was again to extract attribute-value pairs, in this case from the header and body of the mail message, and forward these to the IS. Only two lines were added to the IS interest configuration file to support email requests (Figure 5), and a special AM written, mainly to map email addresses taken from the mail message header into BSCW user login names. The only changes required to the BSCW system itself were to modify the output routines to optionally generate plain text as well as HTML.
HTTP_CM: (simple_http, initialise, bscw.gmd.de, 80)
MAIL_CM: (simple_mail)
(bscw_http, handle_request, [HTTP_CM], {`URL': `^\/bscw\/?'})
(bscw_http, get_icon, [HTTP_CM], {`URL': `^\/icons\/?'})
(bscw_mail, handle_request, [MAIL_CM], {`SUBJECT', `^bscw$'})
Figure 5. The configuration file enabling HTTP and email access to BSCW
In contrast, we have described a `component-based' approach to enabling applications for access from the Web in a more flexible manner using an application integration toolkit. This facilitates more modular and `lightweight' application deployment where specific modules can be integrated as required. Further, separation of the protocol-specific communication handling components from the application modules and provision of an interest-based integration service allows enabling of applications for a variety of other access methods such as electronic mail with few or no changes to the applications themselves.
Our current activities include the extension of the toolkit to provide further Communication Modules--for example, to enable access via FTP. We are also looking at methods to improve performance, such as replacing the request-handling of the IS with a multi-threaded implementation rather than the current forking approach. In the longer term we would like to investigate the possibilities for re-implementing the toolkit with a full object-oriented solution, perhaps using ILU and/or a CORBA-compliant implementation. This may be a step towards bridging the current gulf between the W3 and object-oriented technologies--an area receiving much attention from the W3 consortium [10] and the W3 community in general.
 Jonathan Trevor is a Research Fellow at the German National
Research Centre for Information Technology (GMD FIT.CSCW), where
he is currently a member of the Basic Support for Cooperative
Work project (BSCW). He received both his BSc degree in Computer
Science and his PhD. in the area of Computer Supported
Cooperative Work (CSCW), from the Department of Computer Science
at Lancaster University, UK. His current research interests
include CSCW, the World Wide Web, and distributed systems.
Jonathan Trevor is a Research Fellow at the German National
Research Centre for Information Technology (GMD FIT.CSCW), where
he is currently a member of the Basic Support for Cooperative
Work project (BSCW). He received both his BSc degree in Computer
Science and his PhD. in the area of Computer Supported
Cooperative Work (CSCW), from the Department of Computer Science
at Lancaster University, UK. His current research interests
include CSCW, the World Wide Web, and distributed systems.Richard Bentley s a Research Fellow with the CSCW group of the German National Research Centre for Information Technology (GMD FIT.CSCW), Bonn. He received both his BSc and PhD in Computer Science from Lancaster University, U.K., the latter awarded June 1994 in the area of multi-user interface design for collaborative systems. His current interests include web-based groupware systems, collaborative systems' architectures and groupware user interfaces.
Gerrit Wildgruber Gerrit Wildgruber is student of computer science at the University of Koblenz. He is currently working at his master’s thesis at the German National Research Center for Information Technology, Research Group CSCW. His research interests are CSCW, Distributed Systems and Hypertext.