

Journal reference: Computer Networks and ISDN Systems, Volume 28, issues 7–11, p. 921.
http://www.uni-kl.de/AG-Nehmer/baentsch/
http://www.uni-kl.de/AG-Nehmer/GM.html
http://www.uni-kl.de/AG-Nehmer/sturm/ Department of Computer Science, University of Kaiserslautern, Germany
Abstract: Because of its enormous success, the World-Wide Web created many problems within the Internet, most of them due to its huge bandwidth requirements. Additional applications using the Web's infrastructure for distributed computing [5], e.g., even further increase network load. In this paper, we are presenting a comprehensive application-level approach to solving the Web-induced bandwidth and latency problems within the Internet while staying fully compatible with the current mechanisms of the World-Wide Web.
Keywords: Replication; nameservices; WLIS; failure-tolerance; load balancing; application-level routing.
There are certainly many reasons for this development, like marketing hype or mere trends - it is in to be on the Internet. We cannot do anything about that, but we can tackle some of the technological problems encumbering the World-Wide Web, and with it, the Internet.
The approach presented here is twofold. One part is the enhancement of the concept of proxy-caching to active and automated replication of -possibly sparse- URL namespaces. The second part of this already implemented and available concept is the introduction of application-level nameservices and routing into the Web. With this part of our approach, which we call WLIS (Web Location and Information Service), a first step towards a host-independent naming scheme for documents in general and replication information in particular becomes available on the current Web infrastructure.
The remainder of this paper is structured as follows. In the next section, we are going to briefly highlight the problems that currently strain the Web most and deduce a list of requests for improvements for the WWW. After that, we are reviewing first concepts aimed at solving the problems outlined before. We are continuing with an introduction to a replication scheme we consider sensible within the framework of current WWW software. Since this approach alone does not solve all problems outlined before, and in fact even introduces additional ones, in section 5, a new application-level naming service for the current Web is presented. Section 6 contains an extensive comparison of the concepts presented in this paper with related work in this area. We are concluding with a report on the status of our work, a presentation of further work to be done, and a summary of the advantages our approach has for the Internet in general and the World-Wide Web in particular.
Another problem with the current Web is its technological bias on the single server approach. The necessity to contribute data via exactly one machine with one IP address [4] is due to the property of URLs to contain the hostname indicating the absolute location of the respective information. Though it is possible to use DNS [1] ploys to balance the access load to entire hosts connected to the Internet, the concept of assigning different IP addresses in a round-robin fashion to the same hostname [27] is neither general, scalable, nor flexible enough for the huge community of (potential) service providers in the World-Wide Web. The single-server principle leads to an undue burden of all direct users of any WWW server machine, i.e., the service data providers. In this technological setting, it is the providers' responsibility not to overload the host, a problem they clearly can neither sensibly arbitrate nor solve completely.
A related problem in this context is the visibility of single hosts to end-users: Everyone can see that a particular machine went down, resp. became unreachable because, documents it serves are no longer accessible. With respect to intuitive use of Web services for every single WWW user, this is a non-desirable feature.
These thoughts lead us to establish a request list for a better Web:
The first one is that caches are only filled on demand, i.e., as a user requests data from a caching proxy [6], this proxy not only has to determine whether the data it holds is stale or not, but may -in the first case- also be forced to obtain it from the original server. This incurs a not negligible overhead even in the case of cache hits, i.e., the most favorable case in which data can be delivered from the cache's local disk and need not be completely retrieved over the net. Approaches have been presented dealing with exactly this problem, like time-to-live (TTL) based heuristics [19], caching-in-advance [22], or Push-Caching [12], but there are many further problems to be considered with caching. One of them is the even distribution of cache hits during the course of the day, e.g. The probability to find any item in the cache is roughly the same regardless of the time of day: 30% as reported for remote accesses in [14] also comes close to our measurements on our quite popular campus proxy server. Since this just reduces the bandwidth demands during all times of the day, the huge variances in network bandwidth requirements comparing day- and nighttime are not remedied. A final problem with caching to be mentioned here is that of the democracy of caches: Every item is treated equally. As opposed to real life, most of the time, this is not desirable, since possibly very important documents are flushed from the cache in favor of more recently requested, but less important, data. Being able to control (part of) the contents of the cache would be more sensible in this respect.
In order to solve some of the problems with caching as outlined above, the idea of active data-mirroring as commonplace for large and popular FTP sites, e.g., has to be considered as well. However, a comparatively big administrative overhead has to be taken into account especially, because Web documents tend to be very volatile as compared to FTP data. One further issue is for example the initial overhead of determining where to install a mirror site, and the constant problem of keeping the mirrored namespace consistent with that of the main server. Since this is usually achieved by downloading complete namespaces over night, a huge waste of bandwidth occurs, because often not only the necessary parts are updated. Besides, if the main server's contents are too large, up-to-date mirroring simply becomes impossible. The idea to realize this concept using multicasts from the main server to its mirror sites exists [15], but in the area of the WWW, this would be clearly a major breach with the mechanisms of the Web and the Internet alike. Another problem with mirroring is that of user acceptance: To say the least, not everybody may be aware of its existence, let alone the advantages of mirrors for reduced reply times, and, hopefully, less overall bandwidth usage. Unfortunately, user awareness is required to make mirroring work as desired. Therefore, an automated approach would clearly have a leading edge.
The last point to be discussed in this section is that of a directory service aimed at realizing the fourth issue as pointed out in our request list. Many systems are known in this area, namely DNS [1], or the Network Information Service NIS (formerly known as Sun's Yellow Pages) in the Internet, or ISO's X.500 standard [2]. Although it is tempting to use one of the already established systems on the Internet for a nameservice within the Web, there are several reasons speaking against such a solution. The most important ones are the necessarily massive modifications of an essential service within the Internet, and the need for an integration of semantic knowledge about the Web and its services into such a system. This would burden a stable and efficient service like DNS with an amount of data and traffic not necessary for the general case, i.e., the usual Internet services besides the WWW. Finally, the hierarchical structure of DNS is not well suited to order the chaotic structure of WWW documents and servers. This is why a special-purpose directory service on application-level, i.e., with Web-specific knowledge about protocols, data formats, and user behavior, seems to be a more sensible way to go. The idea of host-independent URNs [3] is the corresponding concept under discussion within the Internet community, though not yet commonly available.
These initial considerations indicate that no approach is readily available to deal with all the problems plaguing today's Web as outlined above. A comprehensive, application-level approach tackling all the issues as presented before, also trying to follow the thoughts as outlined in [17], is going to be introduced in the following two sections.
By merging the administratively simple passive caching with the more work-intensive active mirroring of data into an active caching scheme, we are gaining the best of both approaches. In order to make this term more clear, let us present a typical usage scenario.
At first, a usual WWW server providing some interesting data is set up. Over time, some caches contain part of its data, i.e., its URL namespace. In addition to this scenario describing the current Web, with CgR, caches can now become active replicates for certain, possibly distinct, URL namespaces of some of those servers, whose data they previously only cached. This conversion of caches to Replicated Servers (RS), and of normal WWW servers originating the data, to Primary Servers (PS), is the central concept of CgR (see Figure 1). The conversion may be automatically initiated by appropriate heuristics-based algorithms, or be manually ordered. The latter approach is sensible, if it is known, which data are important for the given user community accessing the RS, while the former primarily helps to lower the latency of all data accesses (previously termed cache hits of non-stale documents).
This idea of actively replicating (sparse) URL namespaces of primary servers to any number of replicated servers does not scale without another twist. The idea here is to create a hierarchy of replicated servers. Only a few RS are known to the primary server. These replicas of the first level may themselves have RS and forward the data they obtained from their PS on to their replicated servers, thus creating a logical tree of servers containing the same data, with the PS at its top.
The conceptual forwarding of data by a WWW server to other servers does not fit into the common infrastructure of the Web, in which data is always obtained in a client-server relationship, where the server passively waits for client requests. However, this is not a real problem, because the realization can work vice versa: A PS only needs to send a simple message (with a special HTTP GET command, e.g.) to its direct RSs. These in turn can then request information about which documents of the PS have changed (again with a simple GET). After this information is known to the replicates, they can pull the modified documents via standard requests from their primary server, and, in case they themselves are replicated, issue the initial `Replicated Documents Have Changed' GET command to their RSs, starting the process recursively again. With this approach, no additional methods, let alone new protocols, have to be introduced into the mechanisms of the WWW.
A minor problem concerning the integration of existing WWW client-side software remains. This is basically the issue of introducing the capability to switch between various servers (PS, RS, and usual WWW servers, resp.) into any Web browser. The initial hook for the solution of this problem is contained within most Web browsers. They are able to select a proxy server [6] for data delivery. A CgR-enhanced proxy is therefore required to make the concept work as desired: A user only has to choose this proxy as his or her gateway to the Internet, and the task of this Client-side Proxy (CP) is to direct WWW requests no longer only to primary (or standard) servers, but if possible, also to available RSs, which are located using the WLIS subsystem presented in section 5. The concept of CPs is especially appealing on the one hand to all users of non-extensible browsers. On the other hand, information providers who want to mask the application-level replicated nature of their server network from the outside world, can set up a CgR gateway via a CP. The availability of highly configurable client side proxy access mechanisms like Netscape's Proxy Auto-Config File based on JavaScript [25] is a clear indication, however, that the functionality of CP and client can be seamlessly integrated into one piece of software. As soon as a stable version of Netscape's Navigator supporting this feature is available, we will implement a CP's functionality using Java/JavaScript.
The CgR concept has many advantages, few of which we are listing here: The first one to be mentioned is naturally that of a more evenly distributed network bandwidth usage. As namespace replicas on the various servers can be updated during low-traffic hours, the peak bandwidth requirements are reduced, while the previously low-traffic hours see more network activity than before. Since the data is now actively replicated, the formerly caching proxy servers need no longer issue validity requests (get-if-modified) to the main servers. This, in combination with the availability of replicated data closer to the clients, is leading to considerably reduced access times for replicated URL namespaces. As these points fulfill the first two requests on our list in section 2, the third advantage to be mentioned corresponds with the third point in that list: The availability of many servers that can answer Web requests authoritatively distributes the load previously sustained by a single server onto all PS and RS alike.
Additionally, beneficial side effects of CgR can be observed as well. With the infrastructure of PSs and RSs in place, the topics of load balancing, (HTTP) traffic shaping, automatic network configuration, and failure-tolerating server groups can be successfully tackled as well. Before this can be done, however, the problem of locating the RSs remains to be solved. It may very well be that the machine next door contains a replicate of a namespace a user is interested in. As long as that information is not available, though, the whole scheme mainly induces additional bandwidth consumption, and just limited benefits. The solution of this problem is the topic of the next section.
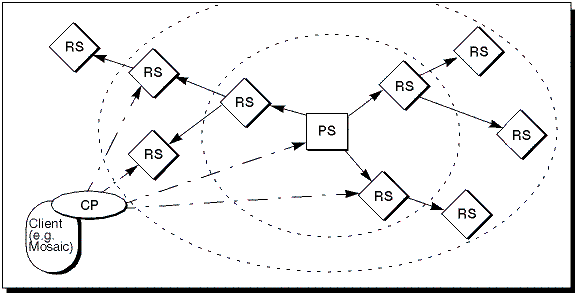
Figure 1
. Overview about the CgR scheme:
The answer to the first question is rather straightforward: WLIS servers can be located anywhere on the Web. Typically, PS, RS, and foremost CPs are the most obvious places where this functionality can be located. Additionally, there may as well be dedicated WLIS servers, which do nothing else than collecting and redistributing WLIS information from and to interested servers and clients alike. In this respect, they are application-level nameservers. Advantages of dedicated WLIS servers include for example load-reduction on document serving machines, the opportunity to introduce global traffic shaping algorithms with them, and the possibility to establish value-adding services like document or person search agents.
The second question of how to generate WLIS information in the first place is also proving quite straightforward to answer. In order to explain the solution, let us assume, no WLIS information were available. In this case, only primary servers know about the locations of replicated servers. Thus, they are the natural agents for the initial generation of WLIS information. The algorithm we devised for creating and distributing WLIS information works as indicated in figure 2: As soon as a WLIS-enabled client (be it a browser, CP, or proxy server) accesses a primary server for any document, the PS passes information about its replicates on as HTTP header options piggybacked with the reply. The client receives this initial WLIS information, stores it for later use, and can start to act accordingly: The next request for any data within the respective URL namespace can be redirected towards one of the replicated servers indicated in the previous WLIS response. This RS again not only returns the respective requested document, but possibly - if it itself is also replicated - as well information about its replicates. This way, the client and all intermediary proxies learn continuously and automatically about replicated server groups.
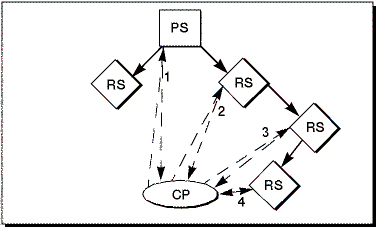
Figure 2
. Schematic Overview of the generation of WLIS information: Over time, (1-4), the CP "learns" the locations of RS
This learning process can also be sped up by inserting information manually about not only CgR servers, but also about already explicitly established WWW mirror sites. With this possibility, the WLIS concept can prove its advantages from day one, since the existing infrastructure of mirror sites that usually have to be addressed and maintained manually, can be accessed completely transparently for every user. This is especially important considering the above-mentioned problem concerning the acceptance of mirrors. This is mainly because users have to explicitly address mirrors, which is an issue solved by the transparent approach of WLIS.
Another advantage of putting this functionality into proxy servers is the opportunity to generate HTML code on the fly. The purpose is to insert WLIS status information into transmitted HTML pages, e.g. hyperlinks making alternative replication sites visible and accessible to the end user. This is possible since Web servers know the data transmission protocol as well as the syntax of HTML; it is sensible since it permits proxy administrators to let the respective user community decide for itself whether to transparently access any host for a certain replicated document, or to obtain data from any specific site, for example for reasons of data freshness.
Finally and above all, WLIS solves our initial problem, namely that of locating replicated server's sites. By being able to tell which servers are RSs to which PSs, the notion of real server groups has come true for the Web. WLIS permits respectively enhanced proxies to choose servers appropriately. This makes it possible to skip unreachable servers, resulting in a kind of (configurable) n-ary degree of server failure resiliency. Additionally, this opens the opportunity to develop heuristics for choosing the server with the highest available end-to-end bandwidth at some given time, implementing load balancing for Web servers and networks alike.
A large amount of research was done in trace-based simulations of Web-accesses, partially with contradictive results: Some found evidence that primary server-initiated data invalidation yields favorable results in terms of bandwidth and latency reduction [12], [18], others state the opposite [19], [24].
Most research groups that presented an implementation in this area can be considered to favor either the server-initiated invalidation, resp. push-caching approach, or adhere to the client-initiated data-pull principle. Some groups also follow both approaches to actually determine the best solution, but none seems to have implemented a highly configurable solution as CgR/WLIS that completely transparently fits into today's installed base of WWW software. The additional advantage of the latter is that server-initiated replication can be applied to some URL namespaces, while at the same time, for example TTL-based client-induced caching strategies can be pursued for other namespaces - all with the same piece of software at the same time. This flexibility, however, comes at a price: CgR/WLIS is not as efficient as other implementations offering part of the functionality [20]. This will be a portion of our further work and we see no fundamental hurdles in obtaining comparable levels of efficiency as reported in [19] e.g.
Another distinguishing issue is the trade-off between low latency and moderate network bandwidth usage. Sometimes the first is considered to be of such utmost importance that the latter is neglected [23]. This concept might be useful in local environments in order to obtain good service for the single user, but if thousands of users would employ the same greedy strategy, the incurred network load would surely increase overall latency again.
Finally, some groups proposed to use wide-area filesystems as underlying infrastructure for the Web in order to tackle the problems as laid out in section 2 [9]. However, besides the proprietary nature of these systems, their non-trivial administration, and their comparatively small installation base, they are not as efficient, extensible, and configurable as the solution presented in this paper. Basically, the reason is that filesystems lack the semantic information making an application-level approach with knowledge about the Web's protocols, infrastructure and document structures superior in this respect.
The implementation has been done by modifying the freely available CERN httpd reference Web server. Its source code grew by about 20% from 16000 to 20000 lines of code. We carefully maintained the distinction between the WWW Library of Common Code [7] and the genuine server code (Library and Daemon subdirectories, resp.). Since only the latter was modified to make CgR/WLIS work as described, we are able to distribute a patch file containing the necessary modifications. An additional advantage of this separation is that we will be able to quickly introduce our changes to the next generation of HTTP server based on the WWW Library of Common Code. In order to realize server failure-tolerance efficiently, we were forced by the current implementation of this server to enhance the WWW Library. This modification, however, is not essential for the presented concept. Nevertheless, this minor change yields a huge advantage in terms of reliance of the Web. Thus, it might be worthwhile introducing the notion of alternative URLs designating the same document into the WWW Library of Common Code.
As the implementation of the CERN server is already highly portable, we also took great care to produce extremely portable code. The developed system compiles and runs successfully on Sun Sparcs (both Solaris and SunOS), Linux PCs, and Alpha Workstations with Digital UNIX 3.0. The code we wrote and precompiled for the platforms indicated above is accessible at http://www.uni-kl.de/AG-Nehmer/GeneSys/WLIS/code.
We implemented this software realizing all the logically distinct components of PS, RS, WLIS server, and CP, within one piece of highly configurable software. It nevertheless is possible to activate only a subset of the overall functionality to make the migration to and the installation of this approach as painlessly doable as possible.
As far as the migration to a CgR/WLIS enhanced Web is concerned, we are seeing three independent ways associated with the three main administrative domains on the net to be appropriate: The client-side software maintainers, the network administration, and the service providers. The first can simply put up a client-side proxy which can immediately start to collect WLIS information (even faked mirror site infos) and act accordingly by redirecting client's requests to the best-suited servers. As more and more (old-fashioned) mirror-sites, or new CgR and WLIS servers are in use, the bigger the benefit for the users of CPs. Network administrators can set up CgR caching proxies which will be immediately advantageous due to caching alone. As they collect (or are manually given) information about sites that should be replicated, they can become RS with all associated benefits discussed in section 4. As a third step, the service providers may set up a CgR/WLIS enhanced server instead of a simple CERN httpd, which will become a PS as the need arises, e.g. if a very well accepted service is run on the respective host. Finally, as should have become clear previously, these distinct migration paths are not imperative. Due to the configurability of this system, features might be combined in any way. It may for example be sensible to set up a caching proxy and a CP at the same time at the same site.
There are many things left to be done as further work. Foremost is the establishment of well-founded heuristics to be used throughout the system. One is needed for example to help decide which URL namespaces to replicate. Another one shall determine the best time to maintain consistency between loosely connected primary and secondary sites. Finally, one is needed to always make the best decision which RS to use; a decision that might depend on the time of day and/or the day of week. Several group's results, in the area of trace-driven simulations [11], [14], [22], [23], or cataloguing [21] e.g., will be taken into account for this purpose. Another topic to be mentioned here is that of write-consistency of replicated URL namespaces. The approach presented only guarantees (if configured accordingly) read consistency: Every user sees the same data regardless of the (replicated or primary) server accessed. As far as writes to Web servers are concerned, no guarantees can be given currently. What should be the semantics of "replicated writes"? Should data sent to an RS immediately propagate through the complete hierarchy of servers up to the PS and down again to all RSs? Or is it possible to live with partial inconsistencies in this area? Since we cannot give conclusive answers on this issue, we are simply dealing with the HTTP methods PUT and POST that realize the writing of data to servers in a different way than with simple data GETs. They are directly and unmodified forwarded to the respective PSs. Thus, in the case of writes modifying server-state, we are gaining nothing by the presented concept, but we also do not lose or change anything as compared with the current infrastructure and semantics of the Web. For the purpose of coming up with sensible solutions for the Web, we are intending to investigate related work in the area of distributed filesystems like the work on the Ficus system [13]. Another issue to be mentioned here is that of protecting the meta-information driving our approach: We will review various ideas in this area, like [16], before trying to introduce a scalable approach to safeguarding WLIS information from tampering, i.e., malign PSs/RSs introducing erroneous WLIS information into the overall system. Dealing with temporarily unavailable or disconnected clients and servers in a CgR/WLIS enhanced Web will also be another interesting field of research in today's increasingly mobile computing environments. Last but not least, we will tune our concept to achieve levels of performance comparable with those reported in [19], or [20] e.g. In addition to the techniques reported in their work, we will also investigate the advantages of persistent HTTP connections [8]. However, as P-HTTP is not part of the standard WWW protocols, we shall also investigate multipart MIME messages [26] for higher efficiency during the RS update-phases in our CgR protocol, e.g.
The advantages of the combination of these concepts are manifold. They not only help to reduce the latency each end-user experiences, but also remedy the extreme variations of network bandwidth usage troubling today's Internet. Additionally, besides a limited form of server failure tolerance, we are gaining network and server access load balancing. The implementation has been made freely available, and enables a simple, smooth, and, for the end users, transparent migration to a CgR/WLIS enhanced Web. In our reference implementation, a special focus has been laid on a high degree of configurability, in order to be able to tune the system to the very dynamic nature of Web services. This is especially important for being able to resolve the partially contradictive findings of other researchers in this area.
The paper was concluded with comments on the status of this work, a preliminary report about first experiences with already installed systems, and a list of further topics to be looked into in this context.
Georg Molter received his diploma in computer science in 1994; he is currently working at the University of Kaiserslautern system software group. His research interest is focused on the field of generic support mechanisms for distributed systems, especially in the context of the problems and possibilities of the rapidly developing high-speed networking technology.
Peter Sturm is a member of the system software group at the University of Kaiserslautern since 1987. He received his diploma (1987) and Ph.D. (1993) both in computer science. His current research interests include distributed operating systems and applications, user interface design, and software engineering.