

Journal reference: Computer Networks and ISDN Systems, Volume 28, issues 7–11, p. 1345.
The statelessness of HTTP makes it difficult for information providers to present complex hierarchical information in an easily navigable fashion. Many non-WWW interfaces allow users to browse through a hierarchical index of information, divided into categories to reduce confusion. This paper describes a program which was developed to create an improved interface for complex hierarchies on the web. Nif-T-nav was developed to solve the problem using standard HTTP; the state information is stored at the client and passed back to the server through the URL. This allows an information provider to present complex information in an easily navigated fashion, reducing the time needed for the user to find the desired data. Keywords: stateful and stateless, interface, navigation, hierarchy, index
Navigation is one of the primary interface challenges for information providers. If an information structure is not easy to navigate, the user will become frustrated and move on without finding the data they're seeking[13]. One way to navigate complex information structures is through a hierarchical index. Generally, this type of information is displayed with a graphical or text-based hierarchical tree, grouping information into categories for easier navigation. This breaks up the complex structure into smaller pieces, causing less confusion for the user. Unfortunately, with the World Wide Web[6], the simplicity of HTML[2] and the statelessness of HTTP[1] force undesired compromises in this type of hierarchical data navigation.
With SGML[9] browsers, as well as most personal computer applications, the situation is quite different. Hierarchical information is represented with an expandable table-of-contents (TOC). As each node is activated, the next level of information for that node is shown indented, directly below its "parent" node. That portion of the tree is thus expanded, giving the user further choices appropriate to their selection. Although complex indexes are often needed on the web, there is no easy way for the information provider to accomplish the tree behavior using HTML. The environment does not support automatic hierarchical behavior for browsing indexed information.
Displaying this type of information should be possible for web page providers, but until now, the solutions have been less than ideal. This paper will first explore the various solutions to this problem, addressing current solutions as well as possible alternatives. Next, the proposed solution will be discussed in detail: how the hierarchy is built; how the "state" is maintained and deciphered; how this creates the desired behavior.
Several different paradigms have been developed to attempt to display this type of information, while maintaining as much of the expected behavior as possible. There are two possible ways to create the tree: statically and dynamically. The two most common solutions are described below. Both of them are static page environments, where the "tree" is simply a maze of pages designed to behave in a tree-like fashion. This allows the user to exploit the "bookmark" feature of his browser with expected results, but as we'll see, the solutions fall short in other areas.
The most common solution (used by yahoo[10], among others) is the following : when a node is activated, a new page is displayed, with only the information pertaining to that node displayed. The node path information is often displayed at the top of the page, to maintain the specific context for the current node. Figure 1 displays this behavior.
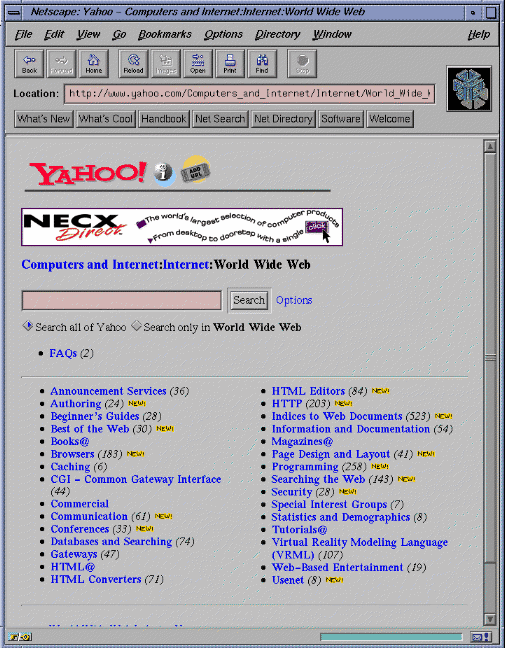
Figure 1. http://www.yahoo.com. Note the parent node information indicated above the selection list.
Nonetheless, this solution does cause a context shift for the user, forcing them into an unnecessarily restricted view, and removing relationships to the other nodes at higher levels. This solution also requires separate pages to be maintained for each node and sub-node on the server.
Another solution, closer to ideal, mimics the correct behavior only to a certain extent. When a single node is expanded, the page behaves as expected. The page is re-drawn with the sub-nodes displayed indented under the activated node. However, when another node at the same level is selected, the first node collapses back to its default state. This unexpected behavior causes unnecessary confusion: the user has no reason to assume there is a limitation on the number of expanded nodes. Figure 2 shows a single-open hierarchy at it's limit. If the "Second Child" is opened, the "First Child" will close.

Figure 2 - The "Single-Open Solution" with a single path open.
This limitation is caused by the implementation; one static page with an expanded node is created for each node in the table of contents. In order to support multiple open nodes, the number of pages required would increase logarithmically. In a static world, this is the best solution, but it still falls short of our desired behavior. The situation becomes even more unwieldy when additional levels are added.
What is needed is an implementation which maintains context for the user, following the expected behavior of a hierarchical text view without adding unexpected behaviors or unwanted context shifts. Simplicity is important, although practicality is imperative: the simplest implementation would be to build a tree of pages for each possible combination of open nodes. As was mentioned above, this would be unwieldy for even the simplest tree, and does not scale at all.
The reality, then, is that the best solution would be a dynamic one. The method should transparently behave as the user expects, without expecting concessions or adding a learning curve. Figure 3 shows the expected behavior for the information view. The ideal program would accomplish this without imposing unnecessary requirements on the client or server; it should be flexible and extensible. It should also support HTML-type behavior, in that using a "bookmark" feature should behave as expected.
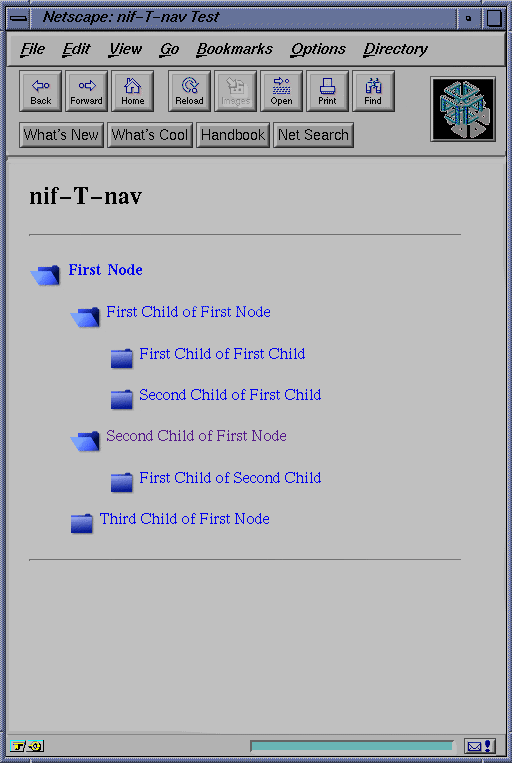
Figure 3 - The ideal interface, displaying multiple open paths at once.
In order to correctly mimic hierarchical tree behavior, the current "state" of the tree must be retained whenever a new node is selected. This introduces a new question: should this information be held at the server or the client? This decision is crucial for the design[8].
In order to maintain the current tree state at the server, some sort of token needs to be assigned to each client. The best implementation of this is the Netscape[11] "cookie." When a cookie-less client contacts the server, the server assigns it a unique cookie to pass back whenever it needs a new page. The state information is stored at the server end, and it accesses this information whenever a new page is requested.
This solution has several drawbacks. The first, most obvious problem is that it is a Netscape-specific solution. This is a show-stopper for many information providers, as they are not able to dictate browser selection to their users. However, there are other challenges for any "cookie" type solution.
One problem involves expiration. The server can never tell if the client is truly "finished" with a page, so an arbitrary expiration time must be selected for each cookie (lest the server's storage capacity become overfull). This means that the user cannot "bookmark" the tree in a particular state. When they return to that bookmark, the "cookie" will have expired, and they will have to re-create the state from scratch. The expiration time will also cause unexpected problems if the user simply stows the browser for long periods of time. Both of these problems cause unexpected behavior of the tree, without adding any value to the solution.
The major drawback is simply that there is too much overhead in this solution. Expiration is not needed, nor is user tracking. The only information that is important for the tree display is the previous state, and the requested state. Storing this information on the server adds unneccesary steps to the completion of the request, as well as causing unexpected tree behavior.
If the information is to be stored at the client side, where should it be kept? It can remain completely invisible to the user using hidden variables, or be passed from the client to the server through the PATH_INFO variable, adding the necessary state information to the URL[12].
Using hidden variables allows complete transparency to the user, and definitely satisfies most of the requirements for state storage, but for one problem: "bookmarking" the tree in a desired state would not work correctly. When the user returned to the page, it would be in the default starting state.
The PATH_INFO is the variable which contains any information in the URL beyond the name of the program itself (if "niftnav.cgi/PATH/INFO" were the HREF for the link, the PATH_INFO would contain "PATH/INFO"). This method has been used to maintain "statefulness" in other Web applications, such as the Xerox PARC map viewer[5]. Using the PATH_INFO variable exposes the state information to the user, removing the complete transparency afforded by hidden variables. However, by using PATH_INFO, the tree can be "bookmarked" in any specific state, and when the user returns to that bookmark, it will look exactly as expected. This is an important advantage which outweighs the loss of privacy for the tree information.
So the ideal program creates the pages dynamically, storing the state information at the client, and passing it back to the server using PATH_INFO. After considering various options, we decided to implement the process using a structure definition file of some sort, and a Perl[7] program, run through CGI[3,4], which uses that file to create the desired pages for the end-user. The definition file needs to have enough structure to define a tree with no limit on depth or number of nodes. The program should be efficient enough to process only those portions of the tree which apply to the current state, to ensure speed and minimal resource usage.
The first definition for our environment will be the structure definition file (the "tree"). We need to create a template that is simple to use, yet completely extensible. The fields required for each node are:
Additionally, we want to have an easy way to describe relationships between nodes (parents / children / peers). The structure that we use for our tree is as follows:
LEVEL | NAME | LABEL | (optional) URL
The "level" and "label" fields are straightforward. The "URL" field is filled in when the author has finished creating a navigable path to an actual information source. The "name" field allows us to record and track node activation; in addition, the name field is responsible for maintaining the relationships between nodes. A child of another node has two identifiable features: its level is one greater than the parent node, and its name begins with the parent node's name.
An example tree might look like this.
1 | ST | "Starting Node" |
2 | STCH | "First Child Node" |
3 | STCHCH | "Next Generation Node" | http://foo.com
2 | STCHI | "Second Child Node" | http://bar.com
In this tree, the relationships between the nodes are as follows: "Starting Node" has a name of "ST", and its level is 1. Any children of "Starting Node" would then have these characteristics: their level would have to be 2, and their names would have to start with "ST". Thus, the direct children of "Starting Node" are "First Child Node" and "Second Child Node". In addition, "First Child Node" has one child, "Next Generation Node," whose name starts with "STCH" and whose level is 3 (one more than "First Child Node").
This tree layout describes the author's intent as follows: When the tree is initially displayed, only "Starting Node" should be visible (it is the only Level 1 node in the tree). If that node is activated, "First Child Node" and "Second Child Node" should be revealed; both of those nodes are Level 2 nodes whose names begin with the name given to "Starting Node." "First Child Node" can be activated to reveal "Next Generation Node." Both "Next Generation Node" and "Second Child Node" directly link to web pages external to the tree structure. <insert explanatory image here>
This design defines a structure from which a tree can be built, without adding extraneous overhead to the creation of the file. It allows indefinite depth as well as unlimited nodes at any particular level. It describes the relationship between nodes in a human-readable and predictable fashion. Now that the tree has been defined, a program must be designed to correctly translate it into a hierarchical index display.
The remainder of section 4 will cover the code and how it creates the desired output. The actual program reads in the above tree file, dynamically creating html pages that match the user's expectations. An algorithm is needed for parsing the fields of the tree and the client-provided state information to create these pages correctly. The program does not unnecessarily process unnecessary entries in the file, restricting its attention to the lines which are potential display targets. Directory lists are used to indent the child nodes, allowing us to use our own icons (menu lists would work equally well, if graphics were not needed).
The PATH_INFO contains the "name" information from the tree file for each link that has been activated. When the tree is in its initial state, each first level node is linked back to the program, with its own name as the PATH_INFO. This allows the client to indicate to the program which node was opened. As the tree is further navigated, additional names are added to the PATH_INFO (separated by "/"'s) to indicate to the program which nodes were previously opened. When a node that has previously been opened is activated again, the program closes that node, along with any children, removing their entries from the PATH_INFO.
As an example, look at the tree listed above. This simple tree has only one node where the level is 1, so the initial page would have only a single visible link:
<a href="niftnav.cgi/ST"> Starting Node </a>
When "Starting Node" is activated, the page would change to the following:
<a href="niftnav.cgi/ST/ST"> Starting Node </a>
<dl>
<dd><a href="niftnav.cgi/ST/STCH"> First Child Node </a></dd>
<dd><a href="http://bar.com"> Second Child Node </a></dd>
</dl>
The page would now have the original link listed, with its children nested in a list below it. Each link would now have a different action associated with it. Activating the "Starting Node" again would "close" that node and all of its children (everything in the list), giving the user a page exactly like the first one. Activating "First Child Node" would display a new page, with all of its current information, adding "Next Generation Node" as a new list item nested below "First Child Node". Activating "Second Child Node" would take the user away from the navigational interface, to the information listed in the indicated URL.
In order to process the tree efficiently and correctly, the program keeps track of the information passed back from the client through the PATH_INFO variable, the highest useable level, and the current level; it also stores the name of the most recently encountered variable, paired with its level. As the names are processed, the current level variable is adjusted appropriately The highest useable level changes when the variable being processed has a higher level than previous variables.
When the program starts, it first checks to see if there is a PATH_INFO variable passed to it from the client. If there is, it creates an array to hold the names from PATH_INFO, and checks that array for duplicates; upon finding a duplicate, it runs the "closing" routine, which removes both copies of the name as well the names of any descendants from the array. This closes the node selected and removes any state information for nodes below it. Once that is done, it processes each entry in the file.
The processing of each entry starts with a check against the array. If an exact match is found within the array, the following occurs: the level and name are stored as an associative pair; the level of the entry becomes the current level, and the highest useable level is adjusted, if necessary. Once that step is complete, the entry moves on to the next stage if its level is not higher than the highest useable level. Otherwise, the program moves to the next entry for processing.
Next, the entry is processed to determine if it will be displayed. For any level, the URL information is determined. If there is a URL indicated, then that is the expansion information for that node. If not, the URL includes the program name, current PATH_INFO, and the name for the current entry. The entry is then processed differently depending on whether the level is 1 or not.
If its level is 1, the entry is displayed regardless of any state information. The previous level is checked to see if any lists need to be closed before creating the entry; also, an anchor is added to the entry if it matches the last PATH_INFO entry activated (to maintain context for the user).
If the level is not 1, a check is made to see if there is a node associated with its (level -1), and if the entry is a direct child of that node. If so, the entry will be displayed with the above-defined URL. Before displaying, the previous level is compared with the current entry to determine if a list needs to be opened or closed before writing out the current node.
To understand how the processes work at a higher level, let's look at the specific scenarios encountered by the program. When the program is started from scratch, no PATH_INFO is passed in. Consequently, neither the current level nor the highest level change, and the program processes only entries with a level of 1; each such entry is written out with either the URL specified for that node, or calling the program with its own unique name as the PATH_INFO.
If one of these nodes is activated, the program is called again, this time with some information in the PATH_INFO variable. It processes each line as before, but when it encounters the line which matches the variable, it creates a name:level pair in an array, increments the current level counter and the highest level counter. Subsequent lines which do not have a level of 1 are checked to see if they are direct descendants of the matched variable, and if so they are displayed.
If a previously open node is clicked again, it creates a duplicate entry in the PATH_INFO. When the PATH_INFO array is checked for duplicates, both copies of the node name are removed from the array, along with the names of any descendants, either direct or indirect. The tree is then processed normally.
As we can see, then, the program correctly responds to the various scenarios as a user browses through the hierarchy. The information is stored at the user's end, able to be "bookmarked" without losing the state of the tree. The program requires minimal involvement by the server, which is only required to process the user's state information when the client requests a new page. Using the PATH_INFO allows us to correctly emulate the behavior we're after, without adding unnecessary complexity to the process.
User interfaces on the web are often far behind what can be found in other applications. It is tempting, as an information provider, to use the limited environment of HTML as an excuse not to improve the interface. This gives the users an impression of the whole web arena as more simplistic and less robust than non-web applications. It forces them through a learning curve, or at the least exposes them to jarring context shifts. Rather than hide behind the limitations of HTML, the web community should find ways to innovate to the ideal, giving users the behavior they're expecting from the tool they're using.
Java allows information providers to offer their users excellent user interfaces, but is limited to browsers designed to accept applets. When working in a more generic Web environment, web developers must work with what is available. The technology used by nif-T-nav is supported by all browsers and servers. No changes need to be made by the user or by the information provider. Using the same technology, other interface improvements are certainly possible. So, rather than compromising the delivery of your data with substandard interfaces, look for ways to do it right.
1. "The Hypertext Transfer Protocol," http://www.w3.org/hypertext/WWW/Protocols/HTTP/HTTP2.html
2. "The Hypertext Markup Language," http://www.w3.org/hypertext/WWW/MarkUp/MarkUp.html
3. "The Common Gateway Interface," http://hoohoo.ncsa.uiuc.edu/cgi/overview.html
4. Steven E. Brenner, "CGI Form Handling in Perl," http://www.bio.cam.ac.uk/web/form.html
5. S. Putz, "Interactive Information Services Using World Wide Web Hypertext", First International Conference on the World Wide Web (Geneva, May 1994), Conputer Networks and ISDN Systems, 27(2):273-280, 1994 http://pubweb.parc.xerox.com/hypertext/www94/iisuwwwh.html
6. T. Berners-Lee, R. Cailliau, A. Loutonen, H.F. Nielsen, and A. Secret. "The World Wide Web, Communications of the ACM," 37(8), August 1994
7. Wall, L., and Schwartz, R.L., "Programming Perl," O'Reilly & Associates, Sebastopol, CA 1990
8. L. Perrochon, "Translation servers: gateways between stateless and stateful information systems," Network Services Conference (London, November 1994), November 1994. ftp://ftp.inf.ethz.ch/doc/papers/is/ea/nsc94.html
9. Charles Goldfarb, "The SGML Handbook," Oxford University Press, 1990
10. Yahoo, http://www.yahoo.com/
11. Netscape, http://www.netscape.com/
12. T. Berners-Lee, "Uniform Resource Locators," 1992. http://www.w3.org/hypertext/WWW/Addressing/Addressing.html
13. M. Galer, S. Haker, J. Ziegler, "Methods and Tools in User-Centred Design for Information Technology," North-Holland, Elsevier Science Publishers, 1992