

Journal reference: Computer Networks and ISDN Systems, Volume 28, issues 7–11, p. 1415.
This paper gives a brief history of the development of the Internet in New Zealand. It describes the use of WWW caching in New Zealand between 1993 and January 1996, concentrating particularly on the deployment of the Harvest Cache software. This software entered production use in October 1995, and less than four months later a single server using it processes the equivalent of around 5% of all Internet traffic between New Zealand and the rest of the world.
The deployment of Harvest Cache software in a number of other countries is briefly described. The results of a survey of New Zealand WWW cache users are presented, indicating that priorities are different for identifiable types of user organisation.
Issues raised by the commercialisation of international bandwidth provision are discussed, and expected development of the Harvest software is outlined.
Keywords: Harvest, New Zealand, World Wide Web, WWW, caching
New Zealand is a technologically-developed country with a population of less than four million located in the Southwest Pacific. Its considerable distance from even its nearest neighbours has influenced the way in which the Internet has developed in New Zealand, as has the highly deregulated telecommunications environment which has existed here in recent years.
The high cost of bandwidth between New Zealand and the major Internet exchanges of the United States' west coast has lead New Zealand universities to use WWW caching more heavily than has been the case in most countries, and this lead has been followed by other New Zealand organisations. Distributed caching using the Harvest Cache software seems now to be increasing the cost savings and performance improvement delivered in the past by stand-alone use of the CERN WWW server software.
This paper is divided into four parts. The first provides background information, giving a very brief history of the Internet and the use of the CERN software in New Zealand, then describing the workings of the Harvest Cache software as they relate to communication between caches. The second part describes the use of the Harvest software in New Zealand to date, and describes the growth of an international network of communicating Harvest Cache servers. The third presents the results of a survey of New Zealand WWW cache users, indicating among other conclusions that universities are substantially more cost-conscious than are commercial Internet Service Providers (ISP's) who use WWW caching. The fourth part considers the effect on distributed caching of the competitive provision of international bandwidth and vice versa and describes expected development of the Harvest software.
The Kawaihiko network began operation in April 1990, using 9600bps leased lines to provide TCP/IP communication among all of the country's seven universities. By 1992, most of these lines had been upgraded to 48kbps.
In early 1992 New Zealand had three research and education networks. DSIRnet was a leased-line network linking sites in the Department of Scientific and Industrial Research (DSIR). MAFnet was a private X.25 network linking Ministry of Agriculture and Fisheries sites. These were interlinked with the universities' Kawaihiko, providing a single TCP/IP network known as Tuia.
In 1992 the government restructured the DSIR and MAF, creating eleven partly-independent Crown Research Institutes (CRI's). In that year a new Tuia network was built, linking all of the country's universities, the CRI's, the National Library and the Ministry of Research, Science and Technology. This new network was built around a frame relay backbone, with digital leased line links to smaller sites. The increased capacity provided by these changes was reflected in increased traffic through New Zealand's Internet link to the outside world, by this time provided by a 128kbps satellite circuit to NASA Ames research centre in California.
By the end of 1995, the highest-capacity connection within the Tuia network was the 512kbps link between The University of Waikato and Victoria University of Wellington. Most links, however, were at 64kbps or 128kbps.
Work began in 1994 on links between New Zealand and major commercial backbone providers, with NSFnet routing ending on 25 April 1995. While a small amount of commercial traffic was carried on New Zealand's international links early in 1995, the volumes involved only became significant from May of that year. By the end of 1995 research and educational institutions accounted for only half of New Zealand's international Internet traffic. Commercial international traffic was divided roughly equally between the Tuia network and other links to the Hamilton gateway.
A major reason for the volume of commercial traffic on the Tuia network is that most universities have in the past acted as commercial ISP's. (The University of Waikato has never had such a role - as gateway and exchange operator it has sought to avoid competing with its customers.) Another reason is geography. New Zealand is a long, thin country, with universities located so that links between them form a logical national backbone. While some ISP's operate long-distance links between particular cities, there is no apparent advantage to the construction of a separate commercial backbone to mirror the Tuia network.
A few ISP's operate their own international links, but in early 1996 the overwhelming majority of traffic to and from New Zealand continues to flow through the Hamilton gateway, now the New Zealand Internet Exchange (NZIX).
Bandwidth across the Pacific has always been far more expensive than bandwidth within New Zealand. This means that the relative costs of the international bandwidth consumed by different organisations can be highly disproportionate to the relative capacity of their links to the gateway site. To ensure that each of the participating universities felt it was getting value for money, the universities adopted a system of charging for international bandwidth based on the volume of traffic to and from each university. Volume charging began in late 1990 [Bro94].
In the interests of predictability, charges were made on the basis of bands of traffic use. A site using, say, between 200MB and 300MB of international traffic per month would pay a given monthly fee so long as their traffic remained in that band. If their traffic consumption exceeded 300MB for a single month only, no additional charge would be made. If their traffic consumption exceeded 300MB for a second consecutive month, they would from then on be taken to be operating in that higher use band, and would be charged a higher monthly fee accordingly. This system was subsequently revised and elaborated, but it remained the case that each university, and later each of the three distinct research and education networks, paid a share of the cost of international bandwidth closely related to its use of that bandwidth.
With income closely related to costs, available international bandwidth could rapidly be increased, as shown in figure 1:
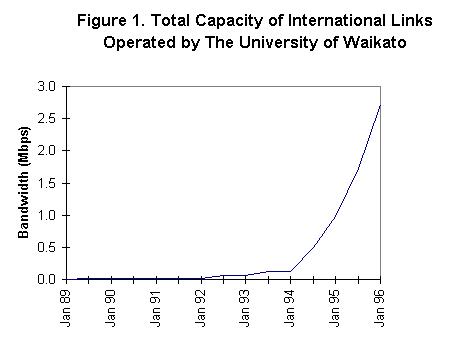
NASA ceased to fund the US end half circuit at the end of 1993. By that time revenue to the gateway's operators was sufficient that no change in service needed to be made as a result of the loss of NASA funding. And because each customer of the international service paid its own way, there was no difficulty later in adding commercial users, who were treated in exactly the same way as educational or research customers (indeed, as was noted earlier, the two groups are not always distinguishable).
A model in which users pay for the traffic they generate might be expected to cause less use to be made of the Internet than would have been the case had services been provided without charge to the end user. The only attempt made in New Zealand to determine the extent of this effect [Car96] failed to find consistent evidence from total traffic figures that the effect even existed. It is interesting to conjecture to what extent demand might have been constrained by restricted performance resulting from limited availability of funds for capacity increases.
In an environment where more efficient use of available bandwidth will produce a direct financial reward to the user, it is to be expected that significant interest will be shown in means of providing such efficiency. Certainly such interest has been shown in WWW caching software.
It is also important that where customers are used to paying by traffic flow, it is easy to establish a basis for charging for the use of a caching server, and hence for the provision of WWW caching as a self-supporting or even potentially profitable service.
By August 1995 the CERN software was being used in New Zealand to provide WWW caching by at least six universities, a polytechnic, five ISP's, the National Library, a state research organisation and one private company whose primary business is not Internet-related.
A CERN server may be configured to use another server as its proxy, referring requests not satisfied by hits on its own cache to that other server. Using this feature, a tree of servers may be constructed, offering the potential of greater savings than could be achieved solely by placing unconnected caches at individual sites.
From May 1995, The University of Waikato made available a CERN caching server, separate from the CERN caching servers used directly by staff and students within the university, to act solely as a parent for caching servers operated by the university's international bandwidth customers. This is known as the "NZGate cache", NZGate being the name under which the university operated international Internet links. This service continued to use the CERN software until November 1995, returning moderate savings in bandwidth to the three universities which used it.
A major weakness of the CERN server is that once it has been configured to use another cache as proxy, it will forward requests to that other cache with no attempt to verify whether the other cache is still functioning. Also, the choice of other cache to be used can only be on the basis of the protocol used to retrieve the object - gopher, HTTP, news or FTP. So while a cache can have separate parents for, say, HTTP and FTP requests, it can have only one parent for HTTP requests. This makes the server at the root of any tree a single point of failure for the entire tree.
It became clear during 1995 that no further development was being undertaken on the CERN software. Since The University of Waikato saw WWW caching as a service of strategic importance to its role as an Internet exchange, alternative software was sought.
Unlike the CERN server, the Harvest Cache software is intended solely as a caching server. It offers high-performance WWW proxy caching, supporting FTP, Gopher and HTTP objects. The software is freely available in both binary and source forms, and is substantially faster than the CERN server software, dramatically so when returning an object as a result of a cache hit. The large difference in speed is due to the fact that while the CERN software forks a new process for each incoming request, a Harvest server forks only for FTP transfers. The Harvest Cache software is implemented with non-blocking I/O, caches DNS lookups, supports non-blocking DNS lookups and implements negative caching both of objects and DNS lookups.
The Harvest Cache software consists of a main server program, cached, a DNS lookup caching server program, dnsserver, a program for retrieving data via FTP, ftpget, and some management and client tools.
On starting up, cached spawns a configurable number of dnsserver processes, each of which can perform a single, blocking, DNS lookup. This reduces the time spent by the server in waiting for DNS lookups. (For a more detailed description of aspects of the software's design, implementation and performance, see [Cha96]. For a description of its internals, see [Sch95].)
A Harvest server may be configured with an arbitrary number of parents and neighbours. The selection of a server from which an object is to be retrieved is based in large part on round trip times. The usual process is shown in figure 2, omitting the case where the server is behind a firewall.
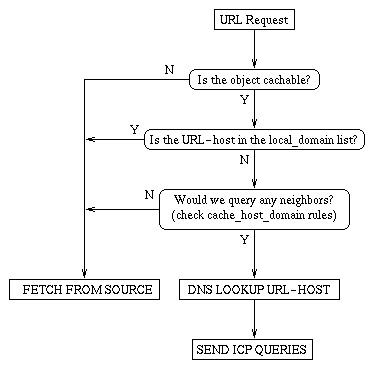
Figure 2. General process for selecting server for retrieval
A server may retrieve an object directly in four cases. First, if the URL requested matches any entry in a stop list in its configuration file. This stop list contains patterns which match objects not to be held in cache. For example, the default configuration file included in the harvest distribution will cause any object whose URL contains the string "cgi-bin" to be treated as uncacheable, and hence not to be requested from any other cache.
Second, if the host identified in the URL is a member of a domain in the configuration file's local_domain list.
Third, the configuration file may contain cache_host_domain records, specifying the domains for whose URL's a parent or neighbour cache is, or is not, to be queried. If due to these restrictions no parent or neighbour is to be queried for the particular URL in question, the object will be retrieved from the source.
If at least one other cache is to be queried, a DNS lookup is performed on the hostname specified in the URL. This is done to ensure the hostname is valid, and because after querying other caches the object may be retrieved from its original host. After this lookup is completed, the process described in figure 3 is begun.
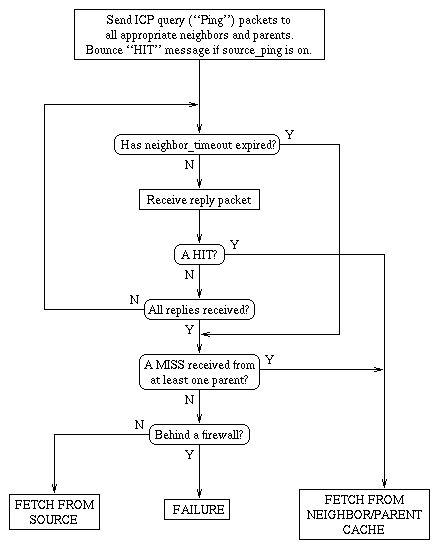
Figure 3. Process of querying neighbour and parent caches
An Internet Cache Protocol (ICP) query packet is sent to each neighbour or parent permitted by the cache_host_domain restricitions. As many replies are expected as queries sent. If the cache is configured with source_ping on, it also bounces a HIT reply off the original host's UDP echo port.
ICP reply packets are received until all have arrived or the neighbor_timeout occurs. The object is immediately fetched from the source of the first HIT reply received. Any parent not using the Harvest software will always return a HIT.
If no HIT is received before the timeout occurs, the object is fetched from the first parent from which a MISS reply was received. If no parent reply was received, whether due to network packet loss or cache_host_domain restrictions, the object will then be retrieved from the host identified in the URL. The query/reply process minimises the risk that requests will be sent to unreachable or non-operational caches.
Note that the terms "parent" and "neighbour" can be misleading, as they imply a hierarchical structure to intercache relationships which is not necessarily present. The only difference between a parent and a neighbour is that a cache miss will not be resolved through a neighbour.
One use of neighbour relationships is to prevent caching loops, in which cache A seeks to retrieve an object through cache B, which in turn tries to retrieve it through cache A. But neighbour relationships can be one-way only. Cache A might use cache B as a neighbour rather than a parent if cache A's administrator felt that using cache B would only be preferable to direct retrieval in the case of a cache hit.
The cache_host_domain restrictions were first seen in a beta release of version 1.3. They were added in response to the undesirable behaviour of a server under test at The University of Waikato, with a server at San Diego Supercomputer Center as its only parent. Because round-trip times between Hamilton and San Diego were much lower than round trip times between Hamilton and some smaller towns in New Zealand, the Harvest server in Hamilton would attempt to retrieve material from those smaller towns via San Diego. It is by means of cache_host_domain entries that traffic patterns in the international Harvest network now in use are controlled.
In September 1995, version 1.3 of the Harvest Cache software was released. Harvest had previously possessed advantages over the CERN software, most important the fact that it was designed to operate in a network of cooperating caches and the much higher speed with which it returned objects, but it was at this time that features were added to Harvest which made it a feasible alternative to CERN.
Unlike the CERN software, a Harvest caching server holds cache metadata (the name of the cache file holding the object, the time when the object expired or will expire) in memory. Version 1.3 was the first release to write that metadata to a log held on disc, allowing a Harvest cache to retain its contents when the server is restarted.
There was also an improvement the server's logging which made billing by volume served to clients possible, as was then being done from the logs produced by the CERN software.
And it was in version 1.3 that it first became possible to restrict from which clients a Harvest server would accept requests, allowing a cache's administrator to dictate to whom that cache would provide service.
On 7 November 1995 CERN software was replaced on the NZGate caching server by Harvest Cache version 1.4 beta. Like the CERN cache before it, this cache resides on a Digital AXP 4000 model 710 server, with 128MB of memory. By January 1996 10GB of disc was available to the cache, though only about half of that was being used.
Canterbury and Massey universities continued to use CERN servers as children to the cache as they had to its CERN predecessor. During November Otago and Victoria universities also set their CERN servers to use this cache as a parent, while the Internet Company of New Zealand, an ISP, set up a Harvest server with the NZGate cache as its parent.
Through November and December problems were experienced with the software's reliability, which resulted in the loss of some of the CERN users as customers. An important factor in perception of Harvest's reliability was the fact that, unlike the CERN server, the Harvest software loads cache metadata into memory at startup. This meant that any software crash was followed by an automatic restart process taking up to an hour. While other Harvest servers would detect that the parent was not serving requests, CERN servers would simply continue to forward requests. Restart times have been substantially reduced in later versions of the software, but this remains a problem where a Harvest server acts as parent to a CERN server.
During November and December the software underwent considerable revision as one beta version after another proved insufficiently reliable. Version 1.4 beta 23 and the subsequent production release version 1.4 patch level 0 have proved stable. Beta 23 was installed on the NZGate cache server on 27 December 1995, and by mid-January all those who had ceased to use the service had returned to using it.
Among influences on the traffic levels shown in figure 4 below is the fact that New Zealand's undergraduate teaching year runs roughly from March to November, with relatively few university or other employees at work in late December and early January. Even so, it seems safe to interpret the pattern of use seen as showing an initial willingness to try using the NZGate Harvest cache as a parent, then a period of disillusionment as reliability problems continued, with increasing confidence in 1996 that stability has been achieved.
Objects served by the NZGate cache to parents or neighbours in the US and Australia account for only a negligible proportion of total traffic.
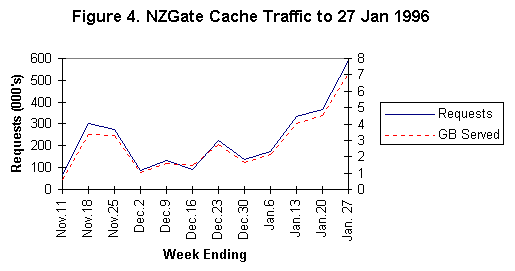
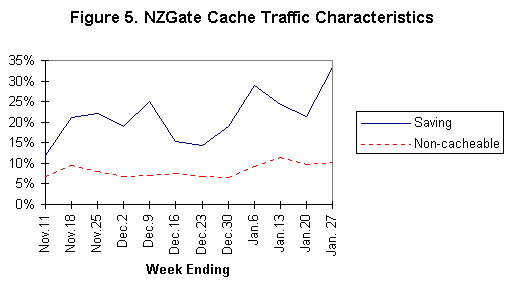
Figure 5 above shows the traffic saving achieved by the NZGate cache as calculated from its logs. The proportion of requests identified in figure 5 as "non-cacheable" are objects whose URL identifies them to the Harvest server as not to be cached. For example, URL's containing a question mark. CERN children forward requests for these to their Harvest parent, where Harvest children do not. One result of this is that the overall NZGate cache hit rate is depressed by the use of CERN rather than Harvest software on child servers.
During January the proportion of the NZGate cache's children made up of Harvest servers has fallen, which may be why the increase in the number of children shown in figure 6 is not associated with consistent improvement in cache hit rate.
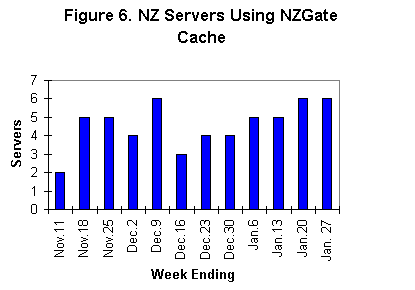
A further large cache is to be added as a child of the NZGate cache before the end of January 1996. Even without that addition, the traffic served to child caches by the NZGate cache in late January 1996 was the equivalent of approximately 6% of all traffic across the links from Hamilton to the USA and Australia, and hence was likely to amount to over 5% of all Internet traffic to and from New Zealand.
Server Location bo.cache.nlanr.net National Center for Atmospheric Research, Boulder, Colorado it.cache.nlanr.net Cornell Theory Center, Ithaca, New York pb.cache.nlanr.net Pittsburgh Supercomputing Center, Pittsburgh, Pennsylvania sd.cache.nlanr.net San Diego Supercomputer Center, San Diego, California sv.cache.nlanr.net FIX West, Silicon Valley, California uc.cache.nlanr.net National Center for Supercomputing Applications, Urbana-Champaign, IllinoisEach of these servers is a Digital UNIX machine with a 266MHz Alpha CPU, 128MB of memory, 10GB of disc and FDDI and ethernet interfaces.
Each acts as parent to the others for particular domains. For example, any request for a file in the nz domain (New Zealand) will be forwarded to the Silicon Valley server, which is parent to the others for that domain. In turn, the NZGate cache is parent to the Silicon Valley server for the nz domain. The assignment of domains to servers reflects the underlying structure of the Internet.
In a similar way, objects are requested of NLANR servers by other Harvest servers outside the US. For example, the Silicon Valley and San Diego servers are parents for the NZGate cache for all objects outside the aq, au, fj and nz domains (Antarctica, Australia, Fiji and New Zealand). So a cachable object from, say, the uk domain requested by a client using the NZGate cache is likely to be retrieved through cache1.nzgate.net.nz, sv.cache.nlanr.net, pb.cache.nlanr.net, and wwwcache.doc.ic.ac.uk in London if that last server responds more quickly to the Pittsburgh server than does the original site.
On the other hand, the NZGate cache will retrieve objects from Australia itself or through a neighbour in Australia, since it is as near in terms of round trip time to Australia's major international gateway as any other Harvest server. While Harvest's application has tended to be described as heirarchical [Cha96, NLA96a], the reality is a little more complex.
The vast bulk of traffic recorded in NLANR's published analysis of their servers' logs [NLA96a] comes from outside the United States. The largest user has to date been the NZGate cache, though the NLANR caches also have relationships with servers in Australia, Germany, Poland, South Africa and the United Kingdom as well as some education and research sites in the United States. The low level of interest from US Internet users and providers may be due to the relatively high availability (or low cost) of bandwidth within the US. Some telecommunications service providers may also be concerned about a US regulatory framework which prevents them from offering "value-added services".
However, "NLANR is supportive of having international clients seed the system, provide the benefit of their domestic experiences, cooperatively develop, deploy and test the performance of mechanisms to encourage efficient and high performance caching." [Cla96]
It has been stated that all of the national and metropolitan servers "are to be stable installations, based on adequate hardware platforms" [Syl95]. However, where the NZGate cache's primary source of funding is charges to users, and NLANR and JANET (see next section) caching work is funded by government, the Polish project's source of funding is unclear. It is currently "using hardware platforms kindly lent by hosting institutions, but these are both used for other purposes and scarce in disk space". [Syl95]
It is difficult to see how a rapid increase in traffic such as that now being experienced by the NZGate cache (see figure 4) could be sustained solely by the use of borrowed equipment. That many New Zealand customers, especially commercial customers, would prefer higher performance to lower price (see below) seems to raise a further question about the advisability of attempting to construct a national infrastructure without a system of charging for use.
A number of JANET sites operate WWW caches, and a few make these publicly available, for example SunSITE Northern Europe at Imperial College and HENSA at the University of Kent [HEN95]. HENSA has received funding to provide a caching service to higher educational institutions.
A survey of JANET sites in progress at the time of writing appeared to show that "around half of the JANET sites run a cache server ... (mostly the CERN or Harvest packages), and that most of these local servers are configured to chain requests on to one of the regional/national servers" [Ham96a]. It found also that most of the sites not operating a cache "would like to deploy one, but were unable to devote the necessary human or computing resources to this task" [Ham96a].
JANET is unusual in that being built on SMDS, its underlying structure is hidden from IP routing protocols [Ham96b], and round trip times between sites tend to be more or less uniform. This makes a tree structure less necessary within JANET than, say, within New Zealand. However, "A configuration which seems to work well in practice with the Harvest software is for an individual site to have several neighbors ... and to make one or two of the national/regional servers into parents for non-UK domains" [Ham96b], with servers retrieving material from within the UK directly. Cache hit rates of up 60% are reported.
Where high international bandwidth costs have driven the use of caching by universities in New Zealand, it is the poor performance delivered by a system in which there is no separate charge for international traffic which has driven the use of caching by UK universities.
A potentially important aspect of UK Internet topology is that all JANET traffic to and from continental Europe passes across the London Internet Exchange (LINX), which is also an interconnection point for UK ISP's. It seems odd that no cache has been located at the LINX.
South Africa also communicates with most of the Internet over very long distances, but the South African user of Harvest which has a mutual-parent relationship with an NLANR server is not a university but a commercial ISP, Pipex Internet Africa. It is too early yet to say what difference if any this will make to the development of WWW caching in South Africa.
Responses are categorised by the type of organisation employing each administrator:
Tertiary ITS Other University ISP Others Total Questionnaires Sent 7 3 5 5 20 Replies Received 6 3 4 4 17
Tertiary ITS Other University ISP Others Question: When did your organisation start using WWW caching software? 1993 2 1994 4 1 2 1 1995 2 2 3 Question: Why? Save Money 5 3 2 3 Improve Performance 2 2 2 Research 2 1 Preserve Bandwidth for other traffic 1 As Part of a Firewall 1 Monitor WWW Use / 1 1 User-level AccountingMany respondents gave more than one answer to this latter question. Both tertiary ITS divisions who gave improved performance as a reason for adopting caching stated that this was secondary to saving money, while a third who adopted caching to save money noted that performance had improved. One "other" company to give saving money as a reason stated that this was secondary to performance improvement.
One ISP which originally adopted caching to save money has continued to use it for performance reasons.
All respondents except one felt that their adoption of WWW caching had been successful. Three ISP's qualified this, expressing concern over specific difficulties in the operation of the CERN software. One administrator for a non-Internet based company felt that his company's allocation of insufficient disc space adversely affected cache hit rate. The administrator who felt adoption had not been successful did not know what hit rate had been achieved by the cache he administered.
Respondents were asked whether they would elect reduced cost or increased performance given the choice now. Their replies are summarised in the following table:
Tertiary ITS Other University ISP Others Performance 2 3 4 1 Cost 4 3
Two tertiary ITS administrators gave cost as the preference of their managers, with performance as their or their users' preference. One university division stated that they preferred performance because they expected improved performance to discourage end users from bypassing the caching system. Another division stated that they preferred performance because their level of use and hence traffic costs were very low.
It seems reasonable to conclude that universities have led the adoption of caching in New Zealand partly from a greater desire to experiment with new software than is shown by most other users, and partly due to greater sensitivity to cost. This sensitivity seems likely to derive from the relatively large total traffic consumption and hence relatively large traffic bills of universities.
Respondents were also asked whether their caching server was using the NZGate cache as a parent or not, and what reasons there were for that decision. The NZGate cache has only been made available directly to organisations already buying international bandwidth directly from NZGate rather than through an intermediary. (All three university divisions who replied use a university cache as a parent to reduce their costs, with one doing so for performance reasons also.)
Question: If you use the NZGate cache as a parent, why? If not, why not? Tertiary ITS ISP Others Yes, to reduce cost 3 Yes, to improve performance 2 1 Yes, because the project is worthwhile 2 Yes, to see how well a heirarchy works 2 No, haven't got around to it 1 1 No, from fear of reduced performance 1 Number able to use service 5 2 1A number of respondents gave more than one answer. The ISP unwilling to use the NZGate cache as a parent stated that once they were able to use Harvest software themselves they would try using the NZGate cache. The university not now using the cache intend to start using it before the end of January 1996.
Glen Eustace, Systems Manager for Massey University, replied that "Our experience with a cache clearly showed it to be worthwhile. I suppose I was interested to see whether a hierarchy of caches would be also. Budgetary issues are making it worth considering anything that gives both improved performance and a lower operational cost." This appears to sum up the appeal of networking caches - universities have led because they wish to find out how well it works, and because it offers reduced cost without performance loss, or performance improvement without financial cost, or some compromise between the two.
Question: What caching software are you using now? Tertiary ITS Other University ISP Others Harvest 1 1 2 CERN 3.0, but moving to Harvest 3 CERN 3.0, but planning to move 1 to Harvest CERN 3.0 or 3.0 pre-release 2 2 2 1 Purveyor 1 Spinner 1The university and both ISP's using Harvest do so in the belief that it provides faster response and handles communication between caches better than CERN. One of these ISP's also described it as reliable, and stated that the code was easier to understand and modify than that for CERN or Spinner. The university using Harvest and one university moving to it expressed concern at the lack of new development of the CERN software.
The university division using Harvest saw it as more reliable than CERN, referring to the fact that the Harvest software will automatically restart the cached daemon on failure.
Two ISP's referred to the CERN server's practice of continuing to load an object after the requested client has aborted the request. This can result in a "server push" graphic being transferred continuously to a CERN server for a theoretically unlimited time, with a severe adverse effect on a cache operator's traffic bill. Clearly the one-line code modification needed to prevent the CERN server from doing this is not as widely known as it could be.
In some cases, CERN is retained because of features it has which Harvest lacks. One university keep the CERN software because they have written a large number of patches for it, and because it allows them to restrict client access to particular web sites, as the current version of Harvest does not. Another university use CERN's ability to get and log a user's login name for each request received from a multi-user computer, information they use to bill according to use of the service in a more precise way than would be possible by billing by machine.
One ISP continue to use CERN rather than Harvest because they set up their retail customers' browsers to read the ISP's home page on startup. Harvest Cache version 1.4 does not support an If-Modified-Since GET, which means that the whole of this page is transferred to each retail user every time their browser starts up, even if their browser already holds a current copy in its local cache. In this situation, Harvest delivers much poorer performance than does the CERN software. This ISP is trialling Spinner [Inf95] at present, but has found it insufficiently stable for production use.
Another ISP continue to use the CERN server because they are unwilling to bear the cost of throwing away the contents of their CERN cache.
The company using Spinner chose it for its speed and for the high speed with which bugs in it are fixed. The company using Purveyor selected it because they wished to run a cache using Windows NT rather than UNIX.
It seems safe to conclude that visible use of a WWW caching product within New Zealand is an important factor in subsequent choices to adopt particular software. While only one organisation stated that it adopted CERN of the recommendation of someone at another site, another mentioned as a reason for using the CERN software a lack of "staff resource to put into investigating alternatives", and as late as June 1995 one organisation adopted CERN in the belief that it was the only WWW caching software available.
As was described in the opening section of this paper, until the end of 1995 the overwhelming bulk of Internet traffic to and from New Zealand travelled over lines operated by The University of Waikato. The building in which those international links terminate also houses the New Zealand Internet Exchange (NZIX), across which flows traffic among ISP's, universities and a variety of other organisations within New Zealand as well as to and from the international links.
Various transitional measures are now in place as the operation of international links to NZIX becomes the business of competing telecommunications companies. Two companies announced in November 1995 that they would be providing international links to and from NZIX by February 1996. Organisations connected to NZIX are now being asked to choose between international service providers.
Yet the NZGate cache now makes up around 6% of total traffic across the exchange, a proportion which seems likely to increase over the coming weeks. The potential exists for the operator of a very large cache to wield considerable power in a bandwidth market, to the disadvantage of bandwidth vendors from whom the cache operator chose not to buy.
It is possible that a cache operator might be able to operate on the basis of purchasing from all bandwidth providers, using route-arbitration software which might be added to Harvest or might operate separately from it. But it seems reasonable to assume that bandwidth providers would seek to compete with such a service by providing their own caches.
Another option is for there not to be a single large cache at such an exchange. Instead, each international bandwidth provider might provide a cache from which customers could choose to take traffic. Harvest Cache software would allow such caches to cooperate as neighbours if the companies operating them chose to work in that way.
Consider three different charging models. The pricing models offered to customers by international bandwidth providers to NZIX are confidential, so it is necessary to use hypothetical cases to illustrate this point.
In the first model, traffic is charged for at a flat rate per, say, megabyte. The return to a cache's users (ignoring hardware and administration costs) is therefore the traffic saving they achieve.
In the second model, traffic is charged for at a fixed rate per megabyte during a peak period, and a lower fixed rate during an off-peak rate. Under such a regime, a cache operator may be able to increase the savings achieved beyond those available with the first model by "cache priming", bringing into the cache during the off-peak period objects which are expected to be read during the peak period.
In a third model, charging is not per unit traffic but is based in some way on peak traffic load. A cache operator will be able to generate very large savings in this case if their cache serves children or end users with very different load patterns when viewed over time. Taking a very simple example, consider a cache which has only two children. The first child is a cache for an organisation which consumes the bulk of its traffic during the day, while the second is for an organisation which consumes the bulk of its traffic at night. In this case the peak load and hence traffic cost for both together may be only slightly greater than for each separately.
The greater the saving which can be made by the manipulation of traffic profiles by cache administrators, the more attractive operation of a cache will be.
In New Zealand at least, these are matters for a future which is weeks rather than years away, but how the introduction of competition to international backbone services and the large-scale use of caching will interact in practice is not yet entirely clear.
The NZGate cache will not be made available simply to any New Zealand organisation wishing to use it. This is partly to ensure that a developing caching network has a structure appropriately related to that of the underlying links. It is also to avoid the administrative work and the complication of relationships with the NZIX's direct customers which would result from direct use of the NZGate cache by a large number of customer organisations.
Work is also under way on Harvest Object Cache version 2.0. This is intended to be a supported piece of software, subject to licence fees and distributed in binary form only.
A beta release of this commercial release is claimed [Dan96a] to have improvements over version 1.4 which are of major interest to New Zealand users:
Performance improvements are claimed for version 2.0, but the author suspects that line speeds within New Zealand are still low enough that most New Zealand users would not see a significant performance improvement as a result of a change solely in server throughput.
It is planned that HTTP 1.1 will be integrated into a later release of the commercial code, after the draft standard "is accepted or at least settles down a bit" [Dan96b]. Implementation of HTTP 1.1 is also among the "general areas" [Wes96] on which NLANR will focus.
Future Harvest software may use a more intelligent mechanism for avoiding cache loops - encapsulating cache signatures in the messages sent between caches. But the existing approach using "manual configuration should suffice for a few more months until there is a more dynamic interface to configure cache resolution." [Cla96]
An issue of increasing importance as the international Harvest network grows is that of determining with what other caches a new server should have parent or neighbour relationships. From version 1.4 patch level 1 on, the Harvest Cache software allows an administrator to have a computer running the Harvest Cache software report back to an NLANR server its latitude and longitude, as well as arbitrary other comments on the caching server's role or relationship to other caching servers. This information is collected and made publicly available at the NLANR Caching project's web site [NLA96b]. NLANR intend to release maps generated from this information.
It is intended that in future the information provided by the caching server will be more tightly defined, following templates issued by NLANR or some other coordinating body. In future versions of the software, it is intended that it will be possible for each server to transmit the information to more than one other server, for example both to a global cache registry and a national cache registry.
In the longer term, however, it will be necessary to replace cache selection based on DNS domains with a means more closely related to the underlying structure of the Internet. While simply replacing DNS domains with IP address ranges in a manual configuration scheme has been proposed as a short-term measure, this will most likely be achieved by the direct use of IP routing protocols. However, using network and transport-layer logic in application-layer code may pose its own problems. And the fact that cache operators may wish for commercial reasons to exercise additional control over cache selection is likely to add further complexity.
The use of WWW caching software has gained wider acceptance in New Zealand than in most other countries, and cached WWW traffic accounts for a higher proportion of international traffic in New Zealand than anywhere else. This has come about in large part because of the visible production use of the software by universities, who in turn have adopted it largely as a cost saving measure. This has happened to a greater extent in New Zealand than elsewhere because in New Zealand the true, and by the standards of the developed world high, cost of international bandwidth is seen by those able to employ means of making more efficient use of that bandwidth.
The relatively small size of the country may also have contributed, with information about successful use of WWW caching spreading more quickly than would have been the case among a larger population of network administrators and managers.
A similar pattern seems to be being followed in the adoption of distributed caching using the Harvest Cache software.
It is interesting that while cost considerations drove all but one of the university implementations of caching, cost was not the dominant factor in use of caching by other organisations. It is therefore possible that publicity for the use of Harvest in New Zealand and elsewhere may lead to the wider adoption of caching in countries where traffic-based charging is not employed.
New Zealand's history of cost-based pricing has fuelled rapid Internet growth in this country, and has encouraged the deployment of WWW caching as a technology to make more efficient use of a resource not perceived as free. New Zealand is now making the transition to competitive provision of international bandwidth at a national exchange after self-funding WWW caching has already become a significant factor in the operation of the Internet here. Even for countries which do not share New Zealand's geographical isolation, there is still much to be learned from New Zealand's rapidly-changing Internet environment.
The Harvest Cache software has proved itself as a fast, reliable, reasonably easy to install means of constructing large-scale caching networks, at a time when no other software with similar functionality exists. So far as anything can be predicted in the Internet of 1996, its future seems assured.
Possibly the real test of WWW caching's implementers will be one of changing perceptions. We shall have succeeded if in New Zealand and other countries where caching is now being introduced, WWW caching is seen not as a service entirely separate from the provision of bandwidth, but as an upper layer in a more intelligent and hence efficient mechanism for the provision of information than has existed before.
Martin Hamilton of Loughborough University was most helpful in describing caching on JANET.
Thanks are also due to John Houlker of Information and Technology Services, The University of Waikato, for his comments on the history of the Internet in New Zealand, and for the information presented in figure 1.
[Car96] Carter, M. and Guthrie G., Pricing Internet: The New Zealand Experience, Discussion Paper 9501, Department of Economics, University of Canterbury, January 1996, ftp://ftp.econ.lsa.umich.edu/pub/Archive/nz-internet-pricing.ps.Z
[Cha95] Chankhunthod, Anawat, The Harvest Cache and Httpd-Accelerator, http://excalibur.usc.edu/
[Cha96] Chankhunthod, A. et al, A Hierarchical Internet Object Cache, Proceedings of USENIX 1996 Annual Technical Conference, pp. 153-163, http://excalibur.usc.edu/cache-html/cache.html or http://catarina.usc.edu/danzig/cache.ps
[Cla96] Claffy, Kimberly, NLANR, private email to the author 26 January 1996
[Dan96a] Danzig, Peter, Harvest Object Cache: Cached-2.0, http://www.netcache.com/
[Dan96b] Danzig, Peter, private email to the author 12 March 1996
[Ham96a] Hamilton, Martin, University of Loughborough, private email to the author 27 January 1996
[Ham96b] Hamilton, Martin, WWW Caching on JANET, 1996, http://wwwcache.lut.ac.uk/caching/janet/
[HEN95] HENSA, The UK National Web Cache at HENSA Unix, http://www.hensa.ac.uk/wwwcache/
[Inf95] Informations Vävarna AB, The Spinner WWW-Server, 1995, http://spinner.infovav.se/
[NLA96a] National Laboratory for Applied Network Research, A Distributed Testbed for National Information Provisioning, 1996, http://www.nlanr.net/Cache/
[NLA96b] National Laboratory for Applied Networking Research, 1996, http://www.nlanr.net/Cache/Tracker/caches/
[Sch95] Schuster, John, Harvest Cache Server Description, Unpublished technical report for the University of Southern California, 1995, http://netweb.usc.edu/danzig/cache-description/harvest_desc.html
[Syl95] Sylwestrzak, Wojtek, WWW Cache in Poland, 1995, http://w3cache.icm.edu.pl/
[Wes95] Wessels, Duane, The Harvest Information Discovery and Access System, http://rd.cs.colorado.edu/harvest/
[Wes96] Wessels, Duane, Untitled, http://www.nlanr.net/~wessels/NLANR-cached.html
[Wor95] World Wide Web Consortium, W3C httpd, http://www.w3.org/pub/WWW/Daemon/