
Table 1. Experimental Data
The Semantic Web is an evolving extension of the World Wide Web (WWW) in which web contents can be expressed not only in natural language but also in a form that can be understood, interpreted, and used by software agents, thereby permitting such agents to find, share, and integrate information more easily.
In general, semistructured data are characterized by the lack of fixed and rigid schema, although, typically, the data have some implicit structure. We propose a method of classifying XML documents and extracting XML schema from XML documents through inductive inference based on constraint logic programming; our goal is to be able to type a large collection of XML approximately but efficiently.
[3] describes an approach to extract schema from semi-structured data. Our research is mainly based on that study. Constraint logic programming is a language that builds a mechanism of restriction cancellation into logic programming; [2] presents a concept of constraint into a relative connotation. [4] proposed to identify relationships between attributes or classes in different database schemas. Details of our study are described in [1].
Our approach has three steps. The first step is XML to predicates, the second step is predicates to rules by induction inference, and the last step is predicates to rules by using ontology. We evaluate similarity of data type and data range by using an ontology dictionary, and XML Schema is made from results of second and last step.
The first step is production of constraints from XML documents. The standard manner is to contain a link-structure and values to extract data into XML (the order of elements is not guaranteed), and to represent the XML using seven base relations defined as follows: Here, Object is O, Class is C, FromObject is FO, ToObject is TO, Label is L, and Value is V.
Next, our approach generates predicates for the data type or data range. In our study, we assumed that the data type and data range were similar to a tag that expresses the same meaning. Moreover, these are expressed by the data type and the regular expression of XML schema. The generated predicate becomes two kinds of the following.
Table 1. Experimental Data
In our study, a classification rule is analyzed using Progol, a system of typical induction logic programming. The background knowledge used for the inductive inference is a hierarchical relation of the amount of the multistep floor features and the connotation relation between the amount of characteristics. In this case, two classification rules were derived using a study that addressed both data of a negative example and a positive example. It is impossible to detect differences from the study data even a little, but the accuracy of the classified category generation is high because usual studies that use data of both a positive example negative example suggest a classification rule that the restriction is strong compared to studies that use only a positive example. The accuracy of the category generation worsens because the restriction of a study that uses only a positive example is weak and one-sided, although it is possible to correspond when using only study data with little difference. Our approach to improving case-sensitive matching is taken by obtaining the retrieval result because the detection results by the restriction of study that uses only a positive example are integrated based on the restriction of a usual study that uses both data of the positive example and the negative example in this study.
The dataset comprises 300 collected XML files, e.g., News-ML and weblogs, from which 81 unique XML documents were made. The results of running our typing algorithm for several synthetic data sets are presented in Table \ref{fig:ex1}. We conducted 100 experiments per test case. Here, XML data were acquired from about a 110-node instance size. `Schema?' in Table \ref{fig:ex0} shows whether the test case has a scheme, e.g. DTD. `Implicit Structure?' in Table 1 shows whether the test case has implicit structures. Evaluation Value is a ratio that uses data of both the positive example and negative example; for the negative example, in the case of 0.8, the data only of 80\% and a positive example takes the meaning of 20\%. Here, the value of the Evaluation Value has three patterns: 0.8, 0.6, and 0.4 for each Test Case. The results of experiments are presented in Table \ref{fig:ex1}. Their corresponding graphs are shown in Fig. \ref{fig:ex2}. Test Number in Table \ref{fig:ex1} and Test Number on the horizontal axis of Fig. \ref{fig:ex2} mutually correspond. %Moreover, the spindle shows the recall ratio and the relevance ratio. When the Evaluation Value was one or less, it did not become 100\%, although Test Case1 with the schema was a very high recall ratio in this experiment (The result shown in Table \ref{fig:ex1} is displayed to three significant digits). %The reason includes the point where the structure of the method of the definition that depends and is resembled exists. %The recall ratio decreases even with the schema when this element increases because it does not refer to the former schema when retrieving it in this study. %Moreover, because the recall ratio depends on the value of tags, it is efficient for the XML dataset with a single schema to store the schema and %the XML data together, and then to use the retrieved existing XML database. In the experiment, the generated restriction was queried, and a method of obtaining the set of necessary data was described. Results confirmed whether man was correct for the relevance ratio and the recall ratio. Test Case 2 with implicit structure : though it doesn't have the schema. The relevance ratio is about 60\% when the recall ratio is about 74\%. Furthermore, it is low when the Evaluation Value is improving. The prevailing purpose of this study is Test Case 2. Future studies are intended to design a technique for displaying the relevance ratio with high accuracy simultaneously to boosting the recall ratio of this case as high as possible.
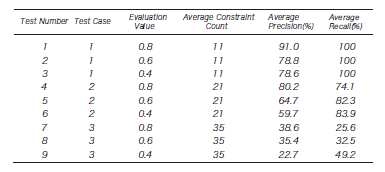
Table 2. Experimental Results A
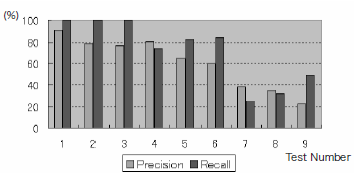
Fig. 1. Experimental Results B
To summarize, this paper proposes a framework for XML retrieval which can find similar meanings of XML within different XML structures. Our approach uses syntax and semantics search; it also uses predicate logic. Results of experiments using real and synthetic data confirmed that our system can compare many kinds of XML documents. The verification of effectiveness for processing the tag structures which have only small differences is a task of future studies, although the present study achieved a highly accurate classification and retrieval for tag structures with a large difference of features.
[1] , On an XML Database System Based on Constraint Logic Programming, WorldComp ICAI, pages 859-865, 2007
[2] , Constraint relative least general generalization for inducing constraint logic programs, New Generation Computing pages 335-368, 1995
[3] , Extracting Schema from Semistructured Data, SIGMOD pages 295-306, 1998
[4] , SEMINT: a tool for identifying attribute correspondences in heterogeneous databases using neural networks, Data & Knowledge Engineering Volume 33, Issue 1, Pages 49-84, Apr 2000