WWW 2008, April 21-25, 2008, Beijing, China.
2008
978-1-60558-085-2/08/04
1
Mining for Personal Name Aliases on the Web
Abstract:
We propose a novel approach to find aliases of a given name from the web.
We exploit a set of known names and their aliases
as training data and extract lexical patterns that convey information related to aliases of
names from text snippets returned by a web search engine.
The patterns are then used to find candidate aliases of a given name.
We use anchor texts and hyperlinks to design a word co-occurrence model
and define numerous ranking scores to evaluate the association between
a name and its candidate aliases.
The proposed method outperforms numerous baselines and
previous work on alias extraction on a dataset of personal names,
achieving a statistically significant mean reciprocal rank of
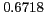
.
Moreover, the aliases extracted using the
proposed method improve recall by

in a relation-detection task.
H.3.3Information SystemsInformation Search and Retrieval
Algorithms
Name alias extraction, Semantic Web, Web Mining
Precisely identifying entities in web documents is necessary for various tasks in the
Semantic Web such as relation extraction, metadata extraction, search and integration of data.
Nevertheless, identification of entities on the web is difficult for two fundamental reasons:
first, different entities can share the same name (lexical
ambiguity); secondly, a single entity can be designated by multiple names (referential ambiguity).
As an example of lexical ambiguity the name Jim Clark is illustrative. Aside from the two most popular namesakes, the formula-one racing champion and the founder of Netscape, at
least 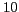 different people are listed among the top
different people are listed among the top 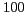 results returned by Google for the name.
On the other hand, referential ambiguity occurs because people use different names to refer to
the same entity on the web. For example, the American movie star Will Smith is often
called the fresh prince in web contents.
Although lexical ambiguity, particularly ambiguity related to personal names, has been explored extensively in the previous studies of name disambiguation [1], the problem of referential
ambiguity of entities on the web has received much less attention.
In this paper, we specifically examine on the problem of automatically extracting the various references
on the web to a particular entity. In contrast to the real name of an entity, we use the term alias
to describe words or multi-word expressions that are used to refer to the entity
(e.g., fresh prince is an alias for Will Smith).
results returned by Google for the name.
On the other hand, referential ambiguity occurs because people use different names to refer to
the same entity on the web. For example, the American movie star Will Smith is often
called the fresh prince in web contents.
Although lexical ambiguity, particularly ambiguity related to personal names, has been explored extensively in the previous studies of name disambiguation [1], the problem of referential
ambiguity of entities on the web has received much less attention.
In this paper, we specifically examine on the problem of automatically extracting the various references
on the web to a particular entity. In contrast to the real name of an entity, we use the term alias
to describe words or multi-word expressions that are used to refer to the entity
(e.g., fresh prince is an alias for Will Smith).
Figure 1:
Outline of the alias extraction method
system.eps
.
|
The proposed method is outlined in Fig.1 and comprises two main
components: pattern extraction, and alias extraction and ranking. To identify the various ways
in which information related to aliases are represented on the web, we use a seed list of
(name,alias) pairs as queries to a web search engine and download text-snippets that contain
both a name and its alias. Here, we use the wildcard operator * to perform
a NEAR query. The operator * matches with one or more words in a snippet.
Figure 2:
A snippet returned for the query ``Will Smith * The Fresh Prince" by Google
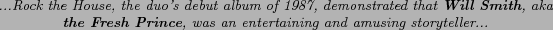 |
Figure 2 shows a snippet retrieved for the query
``Will Smith * The Fresh Prince''. In Fig.2 the snippet contains aka (i.e. also known as), which indicates
the fact that fresh prince is an alias for Will Smith. In addition to a.k.a.,
numerous clues exist such as nicknamed, alias, real name is, nee, which are used on
the web to represent aliases of a name. We create lexical patterns from snippets by replacing the
name and alias respectively by two variables [NAME] and [ALIAS], and extracting
the phrases that appear in between. We repeat this procedure with the reversed query,
``alias * name'' to extract patterns in which alias precedes the name
(e.g., [ALIAS] is an alias for [NAME]). The created patterns can then be
used to query a search engine to find candidate aliases of a given name.
Specifically, we substitute the given name for the variable [NAME] and
* for the variable [ALIAS] and download snippets. The words that match the wildcard
operator in snippets are selected as candidate aliases for the given name.
Using 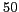 pairs of names and aliases as seeds, we extracted over
pairs of names and aliases as seeds, we extracted over 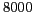 lexical patterns.
Patterns are ranked according to their
lexical patterns.
Patterns are ranked according to their 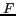 -scores on training data. Top ranking patterns
are shown in Table 1.
-scores on training data. Top ranking patterns
are shown in Table 1.
Considering the noise in web-snippets, candidates extracted using a set of shallow lexical patterns
might include some invalid aliases. Therefore, it is imperative that we identify the candidates
which are most likely to be correct aliases of a given name. We model this problem of alias
recognition as one of ranking candidate aliases with respect to a given name such that the
candidates which are most likely to be correct aliases are assigned a higher rank. We define
various ranking scores to measure the association between a name and a candidate alias using
two approaches: hyperlink structure on the web and page-counts retrieved from a search
engine. Inbound anchor texts of a url provide useful semantic clues related to the resource
represented by the url. We define two words 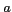 and
and 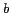 as co-occurring, if they
appear in at least two different inbound anchor texts
as co-occurring, if they
appear in at least two different inbound anchor texts 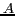 and
and 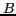 , respectively, in a url
, respectively, in a url 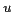 .
Using this definition, we compute
.
Using this definition, we compute 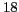 popular co-occurrence measures. Hubs in the hyperlink
graph are automatically detected and co-occurrences in hubs are appropriately adjusted.
Moreover, four page-count-based association measures are computed [2].
All ranking scores are integrated using raking support vector machines to leverage
a robust ranking function. Because of the limited availability of space, we omit the details
of the ranking algorithm.
popular co-occurrence measures. Hubs in the hyperlink
graph are automatically detected and co-occurrences in hubs are appropriately adjusted.
Moreover, four page-count-based association measures are computed [2].
All ranking scores are integrated using raking support vector machines to leverage
a robust ranking function. Because of the limited availability of space, we omit the details
of the ranking algorithm.
Table 1:
Lexical patterns with the highest -scores
|
|
pattern |
|
-score |
|
* |
aka |
[NAME] |
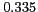 |
|
[NAME] |
aka |
* |
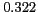 |
|
[NAME] |
better known as |
* |
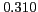 |
|
[NAME] |
alias |
* |
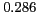 |
|
[NAME] |
also known as |
* |
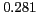 |
|
* |
nee |
[NAME] |
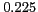 |
|
[NAME] |
nickname |
* |
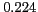 |
|
* |
whose real name is |
[NAME] |
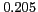 |
|
|
|
|
|
We evaluate the proposed alias extraction algorithm on three datasets
2: English personal names
( names), Japanese personal names ( names) and English place names ( U.S. states).
Personal names datasets include people from various fields of cinema, sports, politics and science.
As shown in Table 2, the proposed method reports high mean reciprocal rank (MRR)
and average precision on all datasets. Moreover, the proposed method outperforms a previously
proposed alias extraction algorithm by Hokama and Kitagawa [3]
(MRR=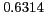 on Japanese names dataset) which uses manually created patterns
specific to Japanese names. Top ranking aliases as extracted by the proposed method
for some names are shown in Table 3. Overall, in Table 3 the proposed
method extracts most aliases assigned in the manually created gold standard (shown in bold).
on Japanese names dataset) which uses manually created patterns
specific to Japanese names. Top ranking aliases as extracted by the proposed method
for some names are shown in Table 3. Overall, in Table 3 the proposed
method extracts most aliases assigned in the manually created gold standard (shown in bold).
Table 2:
Overall performance
|
Dataset |
MRR |
Average Precision |
|
English Personal Names |
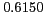 |
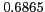 |
|
English Place Names |
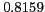 |
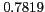 |
|
Japanese Personal Names |
|
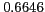 |
Table 3:
Aliases extracted by the proposed method
|
Real Name |
Extracted Aliases |
|
David Hasselhoff |
hoff, michael knight, michael |
|
Courteney Cox |
dirt lucy, lucy, monica |
|
Al Pacino |
michael corleone |
|
Teri Hatcher |
susan mayer, susan, mayer |
|
Texas |
lone star state, lone star, lone |
|
Vermont |
green mountain state, green, |
|
Wyoming |
equality state, cowboy state |
|
Hideki Matsui |
Godzilla, nishikori, matsui |
Table 4:
Effect of aliases on relation detection
|
Real name only |
Real name and top alias |
|
Precision |
Recall |
F |
Precision |
Recall |
F |
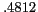 |
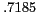 |
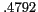 |
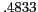 |
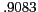 |
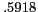 |
We evaluate the extracted aliases on a relation detection task.
First, we manually classify people
in the English personal names dataset into four categories:
music, politics, movies, and sports. Then
we measure the association between two people using the WebPMI [2]
and perform group average agglomerative clustering to form four clusters.
Clustering accuracies with and without using aliases are shown in Table 4.
The use of aliases significantly improves recall (ca. ) and consequently the score.
By considering not only real names but also aliases, it is possible to discover relations that are
unidentifiable solely using real names.
We proposed a lexical-pattern-based approach to extract aliases for a given name.
The extracted candidates were ranked using various ranking scores computed using the
hyperlink structure on the web and page-counts retrieved from a search engine.
The proposed method reported high MRR scores on three different datasets and
significantly improved recall in a relation detection task.
- 1
-
R. Bekkerman and A. McCallum.
Disambiguating web appearances of people in a social network.
In Proc. of WWW'05, pages 463-470, 2005.
- 2
-
D. Bollegala, Y. Matsuo, and M. Ishizuka.
Measuring semantic similarity between words using web search engines.
In Proc. of WWW'07, pages 757-766, 2007.
- 3
-
T. Hokama and H. Kitagawa.
Extracting mnemonic names of people from the web.
In Proc. of 9th Intl. Conf. on Asian Digital Libraries
(ICADL'06), pages 121-130, 2006.
Footnotes
- ... Bollegala1
- Research Fellow of the Japan Society for the Promotion of Science (JSPS)
- ... datasets2
- www.miv.t.u-toyko.ac.jp/danushka/aliasdata.zip