Guoliang Li ![]() Jianhua Feng
Jianhua Feng ![]() Jianyong Wang
Jianyong Wang ![]() Xiaoming Song
Xiaoming Song
![]() Lizhu Zhou
Lizhu Zhou ![]()
Department of Computer Science and Technology, Tsinghua University, Beijing 100084, China
{liguoliang,fengjh,jianyong,dcszlz}@tsinghua.edu.cn;songxm-07@mails.tsinghua.edu.cn
WWW 2008, April 21-25, 2008, Beijing, China.
2008
978-1-60558-085-2/08/04
Guoliang Li ![]() Jianhua Feng
Jianhua Feng ![]() Jianyong Wang
Jianyong Wang ![]() Xiaoming Song
Xiaoming Song
![]() Lizhu Zhou
Lizhu Zhou ![]()
Department of Computer Science and Technology, Tsinghua University, Beijing 100084, China
{liguoliang,fengjh,jianyong,dcszlz}@tsinghua.edu.cn;songxm-07@mails.tsinghua.edu.cn
This paper studies the problem of unified ranked retrieval of
heterogeneous XML documents and Web data. We propose an effective
search engine called SAILER to adaptively and versatilely
answer keyword queries over the heterogenous data. We model the Web
pages and XML documents as graphs. We propose the concept of
pivotal trees to effectively answer keyword queries and
present an effective method to identify the ![]() -
-![]() pivotal trees
with the highest ranks from the graphs. Moreover, we propose
effective indexes to facilitate the effective unified ranked
retrieval. We have conducted an extensive experimental study using
real datasets, and the experimental results show that
SAILER achieves both high search efficiency and accuracy,
and outperforms the existing approaches significantly.
pivotal trees
with the highest ranks from the graphs. Moreover, we propose
effective indexes to facilitate the effective unified ranked
retrieval. We have conducted an extensive experimental study using
real datasets, and the experimental results show that
SAILER achieves both high search efficiency and accuracy,
and outperforms the existing approaches significantly.
H.2.8Database Applications Miscellaneous
Algorithms, Performance, Languages
Keyword Search, XML, Web Pages, Unified Keyword Search
Existing web search engines cannot integrate the information from
multiple interrelated pages to answer keyword queries meaningfully.
The next-generation Web search engines require
link-awareness, or more generally, the capability of
integrating the correlative information that are linked through
hyperlinks. For example, to search for the conferences including the
topic of ``Information Retrieval" and held in
``Beijing 2008", users issue a keyword query of
"Conference 2008 Beijing Information Retrieval" to a search
engine like GOOGLE. As we all know, "WWW 2008" is
held in Beijing and ``Information Retrieval" is one of its
major research topics, but surprisingly, the homepage of
"WWW 2008" is not in the top-10 results and not even in the
first one hundred answers either. This is because "WWW
2008" splits its information into several pages methodically. The
page of IMPORTANT DATE contains keywords
"2008,Conference", "Information Retrieval" is
contained in the page of CALL-FOR-PAPER and
"Beijing" is included in the homepage. Consequently,
existing search engines often include a number of false negatives
due to the limitation of their models which take only a list of
individual pages as the result but neglect the fact that
interrelated pages linked by hyperlinks may be more meaningful.
However, this is not an ![]() problem but ubiquitous over the
Internet.
problem but ubiquitous over the
Internet.
As XML is widely recognized as the data interchange standard over the Internet, the research community has been introducing keyword search capability into XML documents[3,4,5]. To the best of our knowledge, few existing works could be universally applied to Web pages and XML documents. Therefore, providing both effective and efficient search ability over such heterogeneous collections within a single search engine remains a big challenge. This calls for a framework for indexing and querying over large collections of heterogeneous data. To address these problems, we propose an effective search engine SAILER based on Structure-Aware Indexing for unified retrievaL of hetERogeneous XML and web documents. As opposed to the traditional search engines, which return a list of individual pages as the results, SAILER extracts a set of relevant pages, which are highly interrelated and related to queries.
We model the Web pages and XML documents as graphs, where the nodes are respectively pages and elements and links are hyperlinks between pages and parent-child relationships (or IDREF) in XML documents. We can translate the problem of keyword search over the heterogeneous data to the problem of finding the connected trees with minimal cost over the graphs, which contain all or a part of input keywords, called Steiner trees. However, it is fairly difficult to extract the Steiner trees in a large graph, which is NP-hard [1]. Alternatively, we devise indices for facilitating keyword-based search over large graphs.
![]() =
=![]() {
{![]() (
(![]() ,
,![]() )
)![]()
![]() },
},
where ![]() directly contains
directly contains ![]() and
and
![]() (
(![]() ,
,![]() ) denotes the distance between
) denotes the distance between ![]() and
and ![]() .
.
Pivotal trees are compact connected trees in the graph, which contain all the input keywords, and therefore they can be taken as the answers of keyword queries.
We present how to effectively rank the pivotal trees. Given a
pivotal tree ![]() and a keyword query
and a keyword query
![]() =
=
![]() , we present Equation
1 to rank the pivotal tree
, we present Equation
1 to rank the pivotal tree ![]() .
.
where ![]() (
(![]() ,
,![]() ) denotes the term frequency of
) denotes the term frequency of ![]() in
in ![]() ;
; ![]() (
(![]() ) denotes the inverse document frequency of
) denotes the inverse document frequency of
![]() ;
; ![]() denotes the normalized term length of
denotes the normalized term length of ![]() and
and
![]() =
=
![]() , where
, where ![]() denotes the number
of terms in
denotes the number
of terms in ![]() and
and ![]() denotes the number of nodes in
denotes the number of nodes in
![]() ;
; ![]() is a constant and usually set to 0.2.
is a constant and usually set to 0.2.
If ![]() indirectly contains
indirectly contains ![]() , we present Equation
3 to compute
, we present Equation
3 to compute
![]() .
.
where ![]() is an attenuation factor. Obviously, the
larger distance between
is an attenuation factor. Obviously, the
larger distance between ![]() and
and ![]() , the less relevant between
them. We experimentally prove that
, the less relevant between
them. We experimentally prove that ![]() is usually set to 0.8.
is usually set to 0.8.
Note that,
![]() can be computed based
on Equation 2, as
can be computed based
on Equation 2, as ![]() directly
contains
directly
contains ![]() and
and
![]() can be pre-computed
off-line. Accordingly, we can score the nodes that indirectly or
directly contain the keywords based on Equation
2 and Equation
3.
can be pre-computed
off-line. Accordingly, we can score the nodes that indirectly or
directly contain the keywords based on Equation
2 and Equation
3.
We note that
![]() in Equation
2 and Equation
3 can be pre-computed off-line and
thus we can materialize such scores into the index. The entries of
the index are the keywords that contained in the graph. Different
from inverted indices which only maintain the nodes that directly
contain the keyword, each entry of index preserves the nodes that
in Equation
2 and Equation
3 can be pre-computed off-line and
thus we can materialize such scores into the index. The entries of
the index are the keywords that contained in the graph. Different
from inverted indices which only maintain the nodes that directly
contain the keyword, each entry of index preserves the nodes that
![]() or
or ![]() contain the keyword in the form of a
triple
contain the keyword in the form of a
triple ![]() Node, Score, Pivotal Path
Node, Score, Pivotal Path![]() , where the
Score is the assigned score of the keyword in the
Node, and Pivotal Path preserves the path from
Node to the corresponding
, where the
Score is the assigned score of the keyword in the
Node, and Pivotal Path preserves the path from
Node to the corresponding ![]() . Accordingly, the
index captures the rich structural relationships as each entry
preserves the paths from a given node to the corresponding pivotal
node.
. Accordingly, the
index captures the rich structural relationships as each entry
preserves the paths from a given node to the corresponding pivotal
node.
We have designed and performed a comprehensive set of experiments to
evaluate the performance of our approach. We crawled a huge amount
of real data from the Internet. There are four types of data in our
dataset: ![]() the homepages of top conferences, such as WWW, SIGIR,
SIGMOD and so on;
the homepages of top conferences, such as WWW, SIGIR,
SIGMOD and so on; ![]() the hompages of research groups;
the hompages of research groups; ![]() the
homepages of researchers;
the
homepages of researchers; ![]() XML, PDF, WORD and PPT documents.
There were approximate 100,000,000 documents. The experiments were
conducted on an Intel(R) Pentium(R) 2.4GHz computer with 1GB of RAM.
The algorithms were implemented in Java. We compared SAILER
with state-of-the-art methods, Information Unit [6],
and SphereSearch [2]. We selected one hundred
queries for the experiments. We gave the elapsed time of the first
ten queries and the average precision of all the queries as
illustrated in Figure 1.
XML, PDF, WORD and PPT documents.
There were approximate 100,000,000 documents. The experiments were
conducted on an Intel(R) Pentium(R) 2.4GHz computer with 1GB of RAM.
The algorithms were implemented in Java. We compared SAILER
with state-of-the-art methods, Information Unit [6],
and SphereSearch [2]. We selected one hundred
queries for the experiments. We gave the elapsed time of the first
ten queries and the average precision of all the queries as
illustrated in Figure 1.
In this paper, we have investigated the problem of unified retrieval over heterogeneous web pages and XML documents. We modeled the heterogeneous data as graphs and identified the pivotal trees to answer keyword queries. We proposed indexes for facilitating the identification of pivotal trees. We have conducted an extensive performance study to evaluate the search efficiency and quality of our method. The experimental results show that our approach achieves both high search efficiency and quality, and outperforms the existing approaches significantly.
This work is partly supported by the National Natural Science Foundation of China under Grant No.60573094, the National High Technology Development 863 Program of China under Grant No.2007AA01Z152 and 2006AA01A101, the National Grand Fundamental Research 973 Program of China under Grant No.2006CB303103.
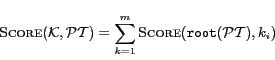
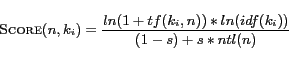
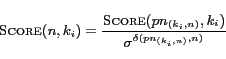
![\includegraphics[scale=0.6]{Execution.eps}](pp075-li-img47.png)