Copyright is held by the World Wide Web Conference Committee (IW3C2).
Distribution of these papers is limited to classroom use, and personal use by others.
WWW 2008, April 21-25, 2008, Beijing, China.
ACM 978-1-60558-085-2/08/04.
ABSTRACT
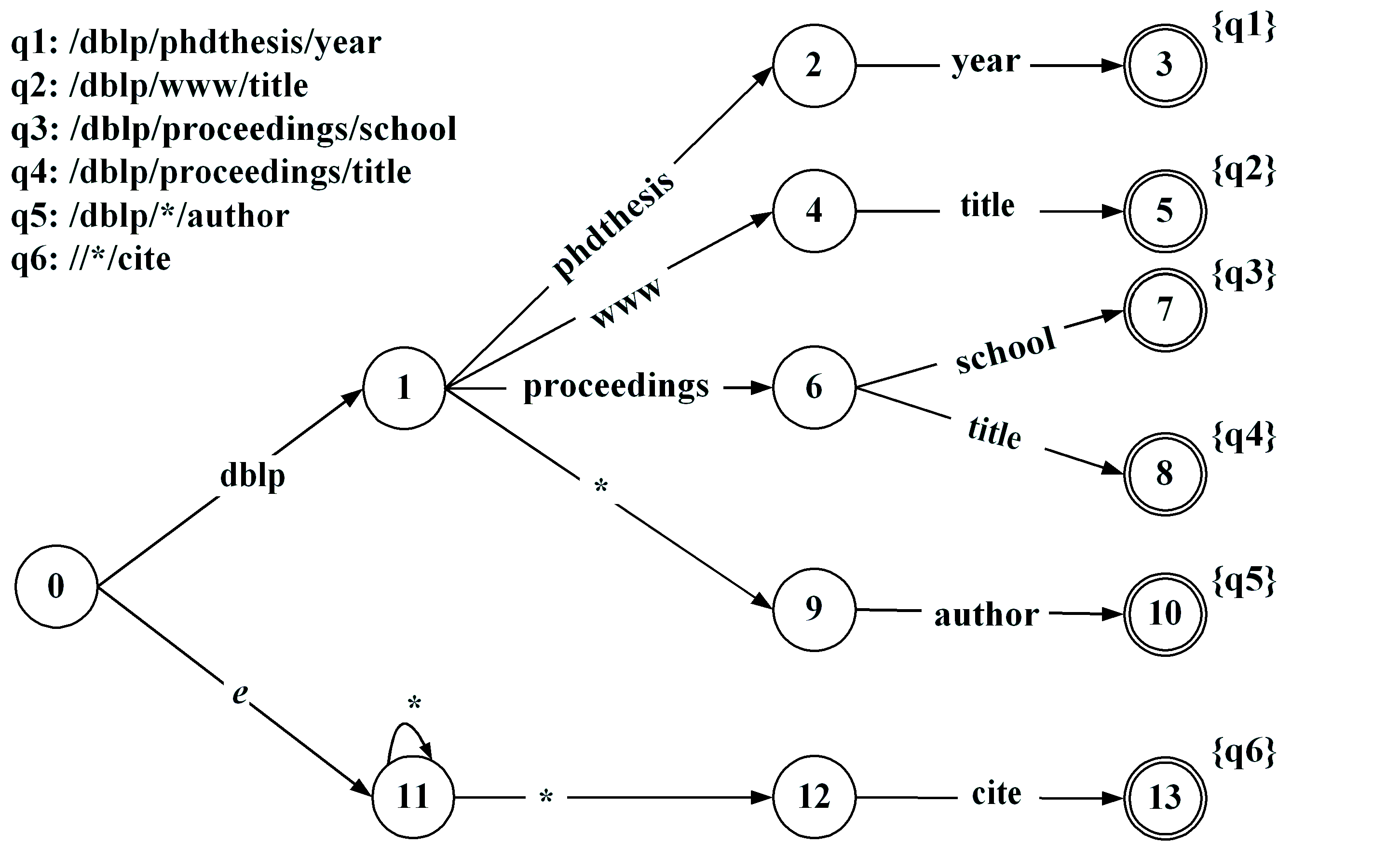
We present a novel approach for filtering XML
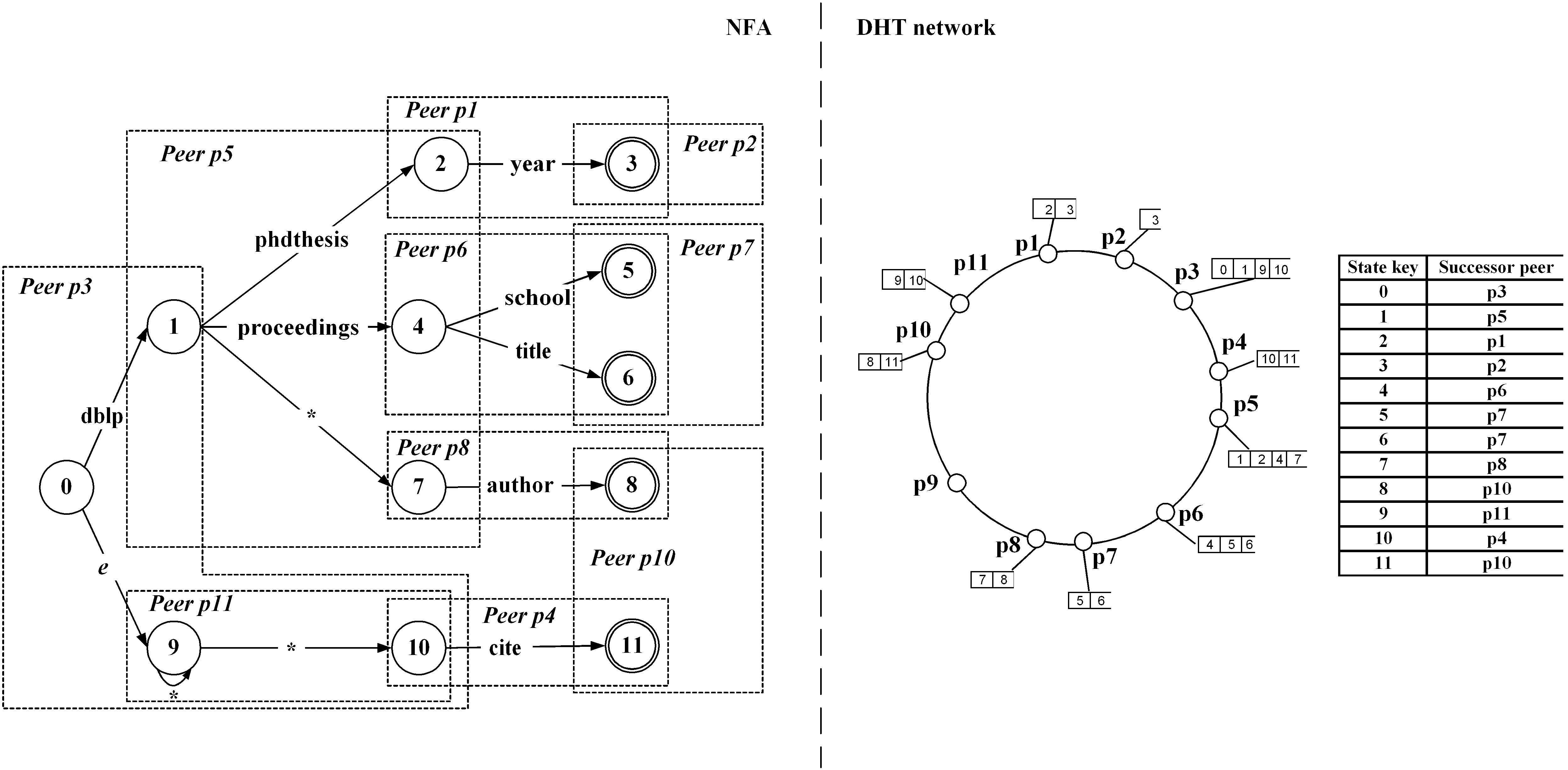
documents using nondeterministic finite automata and distributed
hash tables. Our approach differs architecturally from recent
proposals that deal with distributed XML filtering; they assume
an XML broker architecture, whereas our solution is built on top
of distributed hash tables. The essence of our work is a
distributed implementation of YFilter, a state-of-the-art
automata-based XML filtering system on top of Chord. We
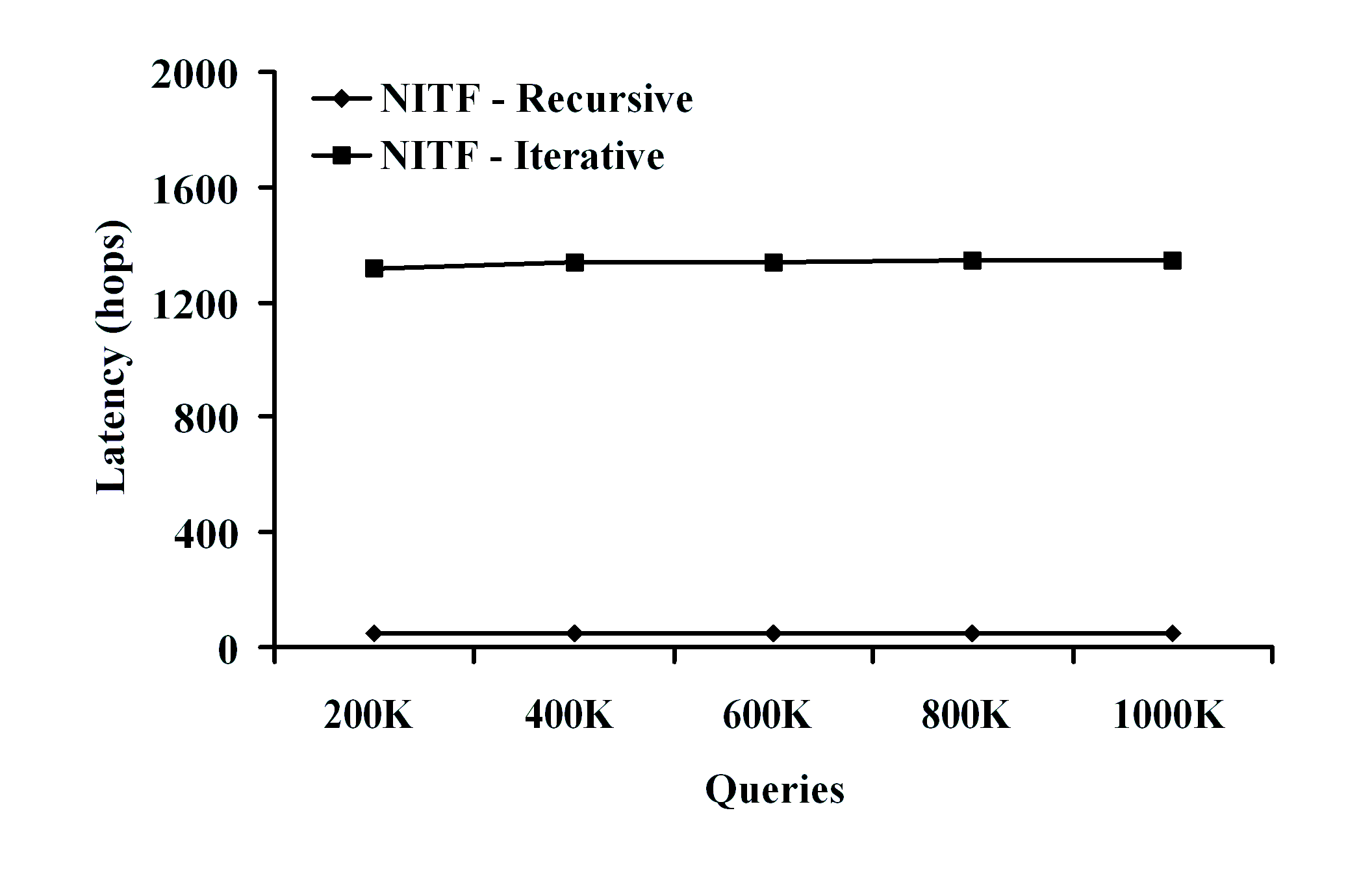
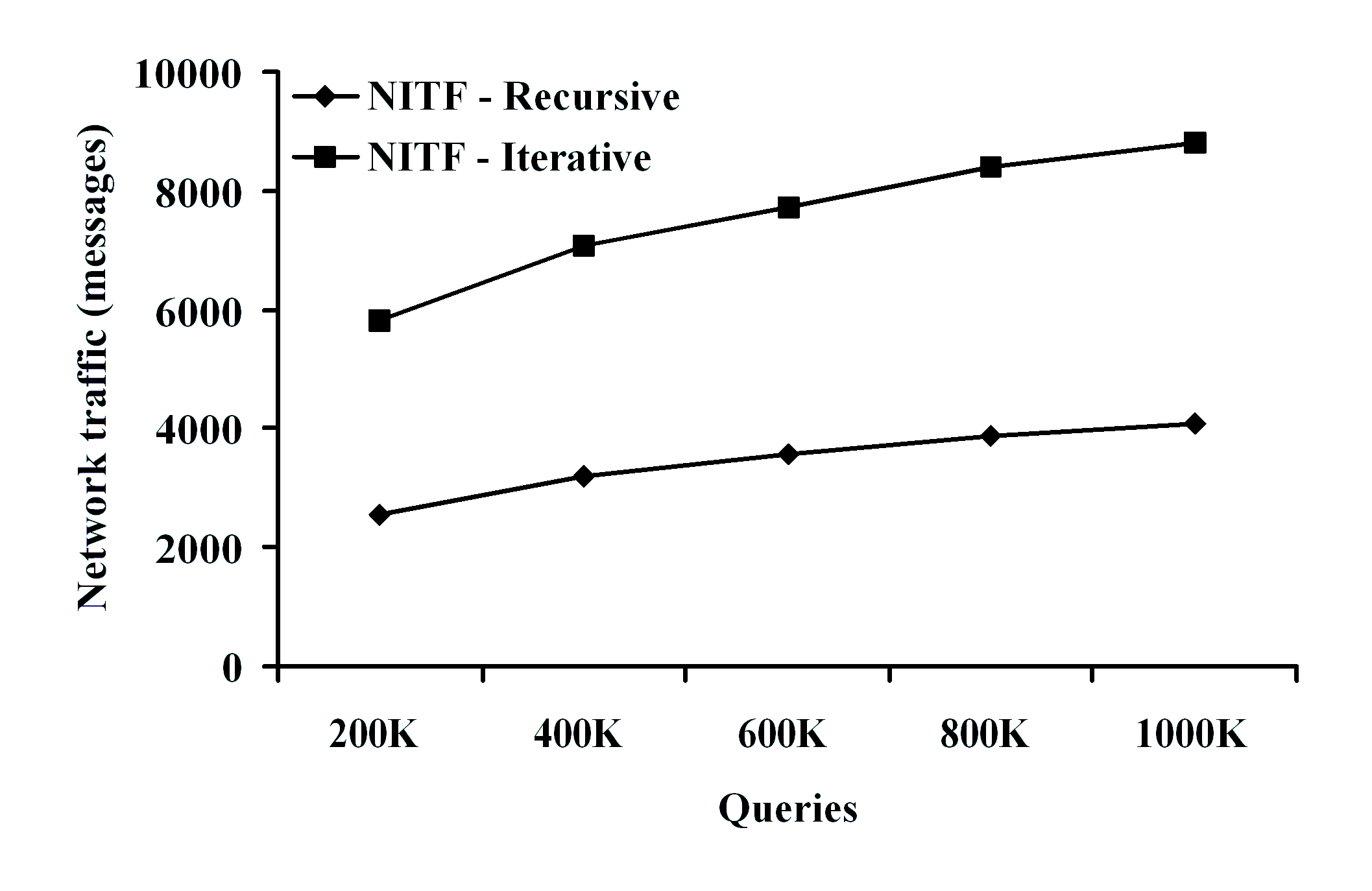
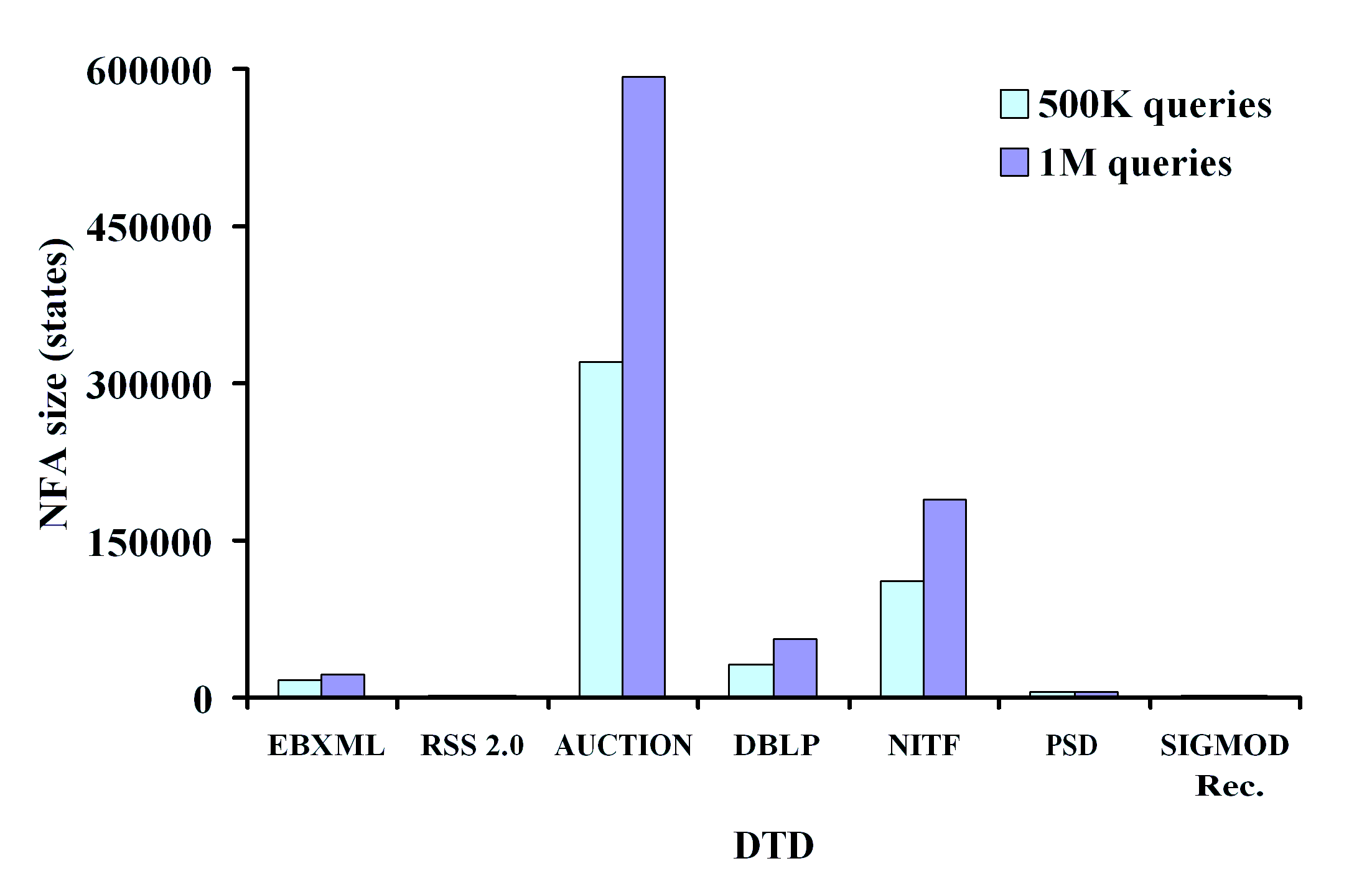
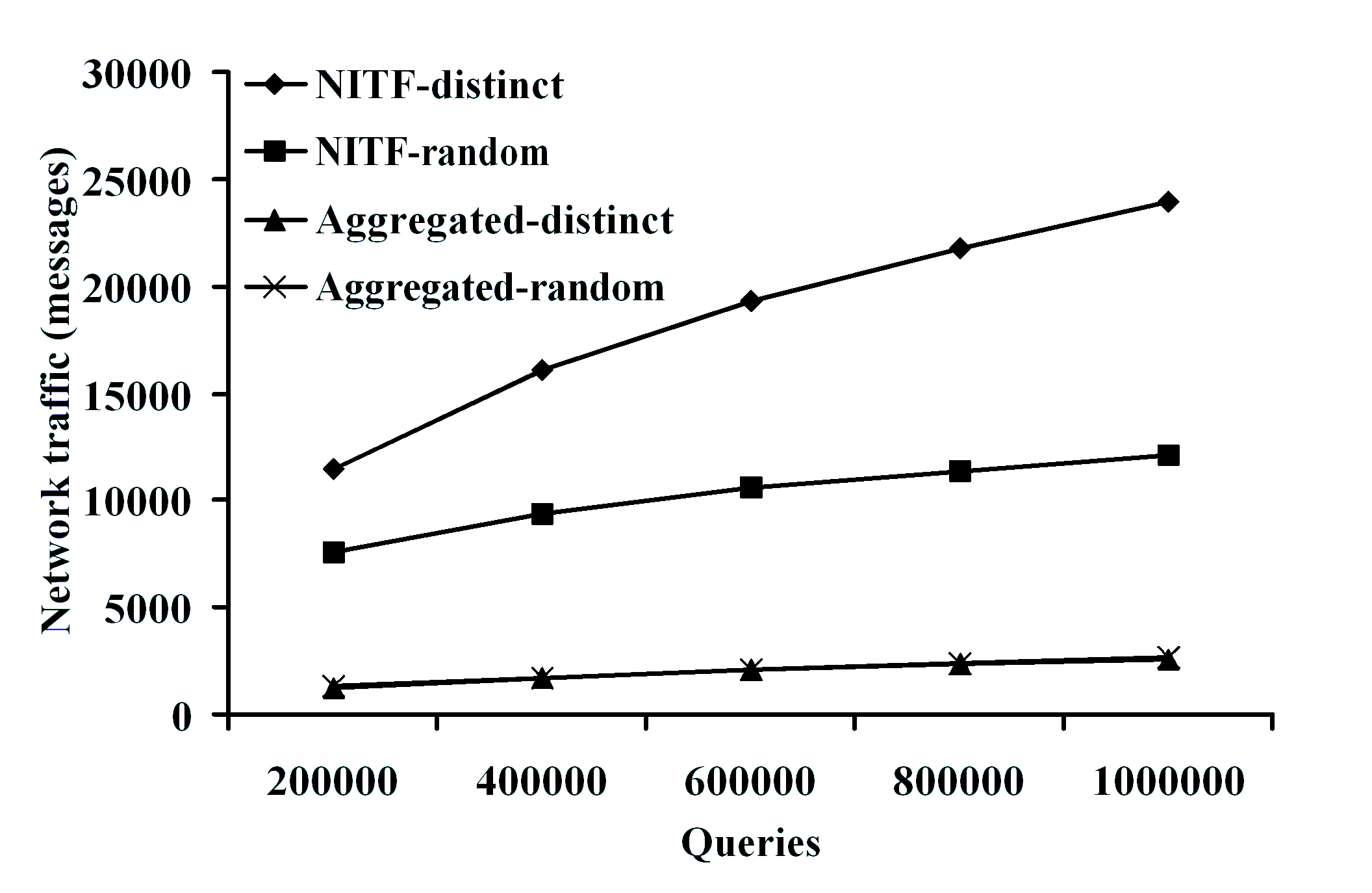
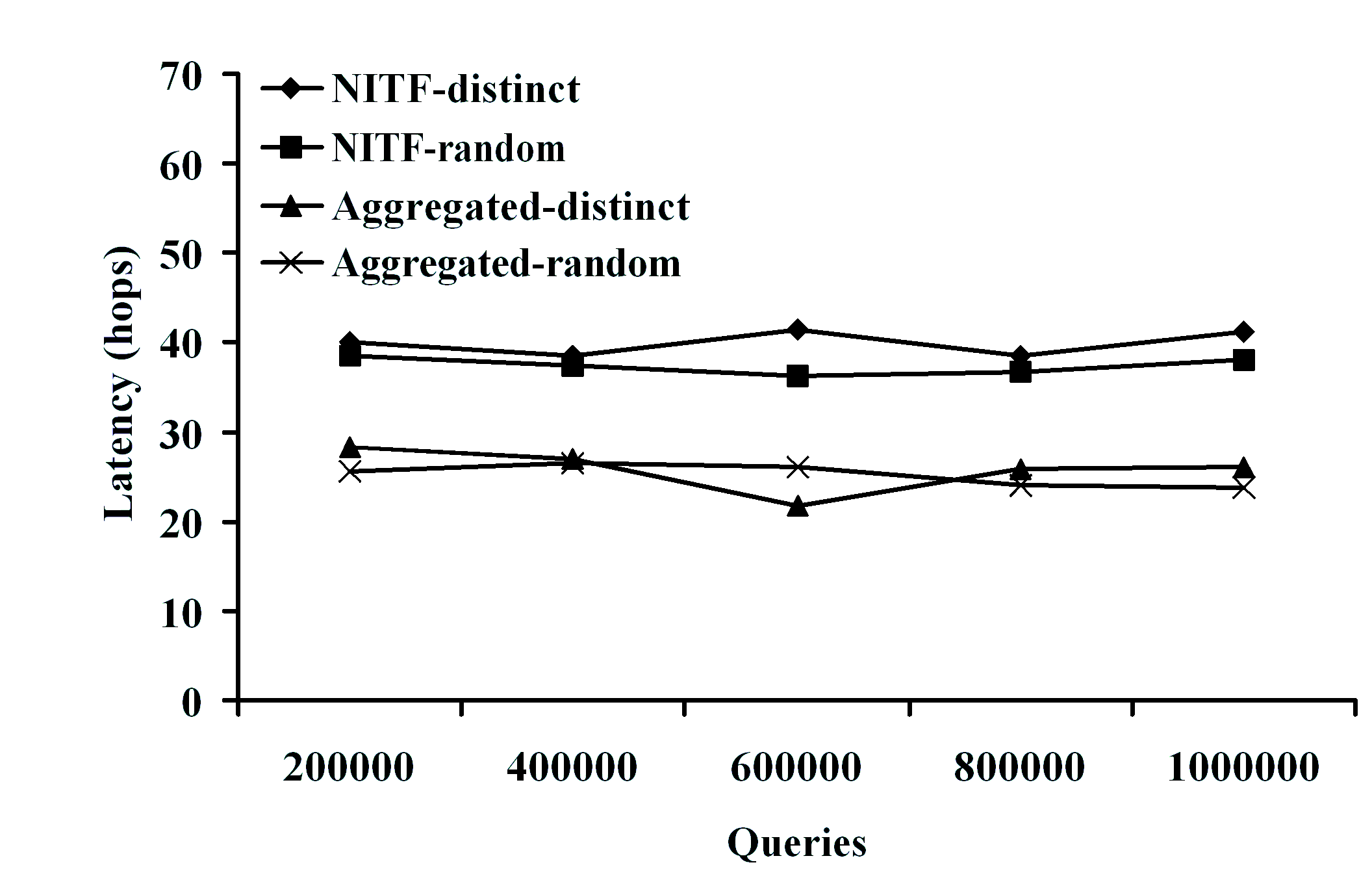
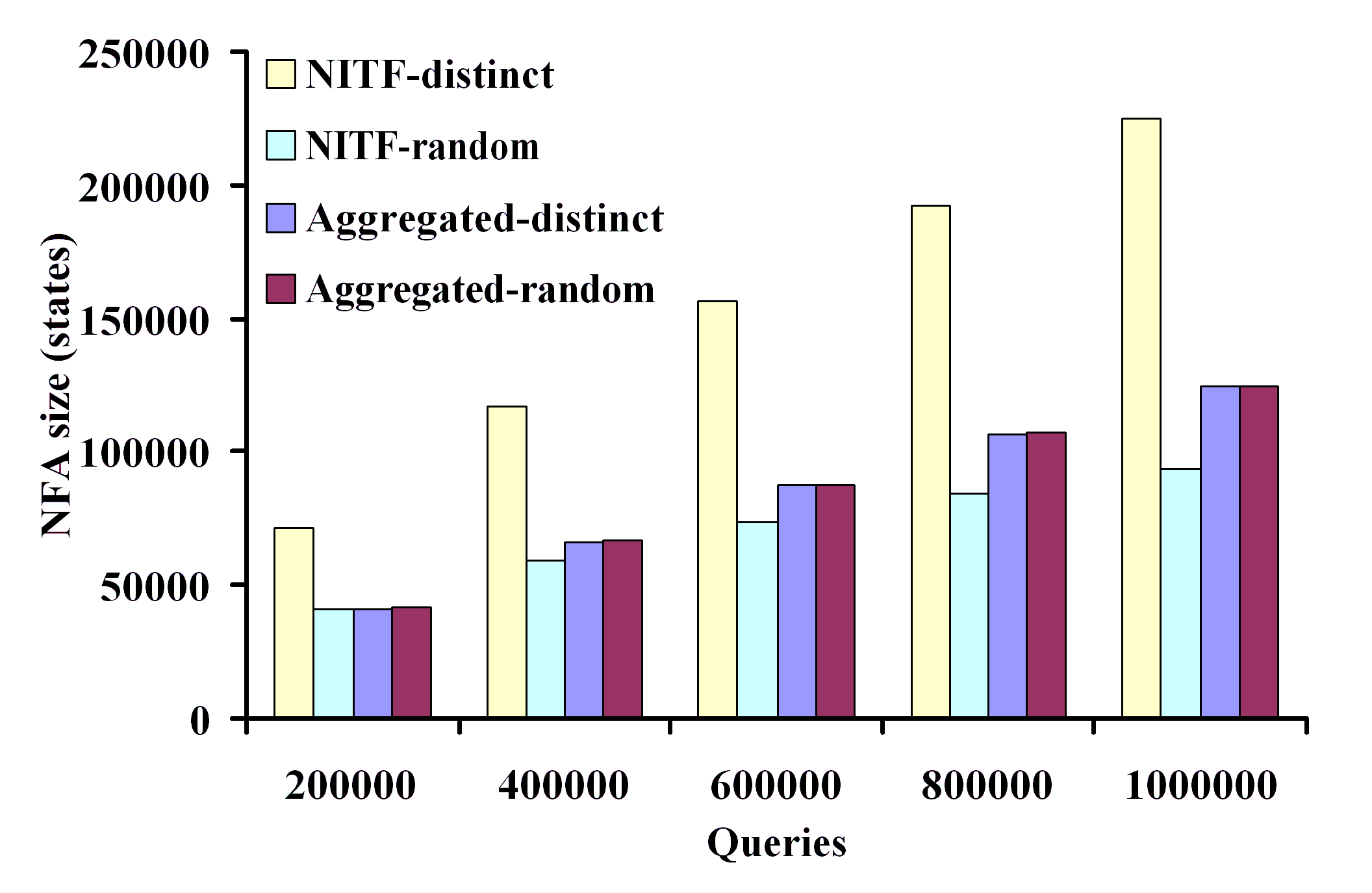
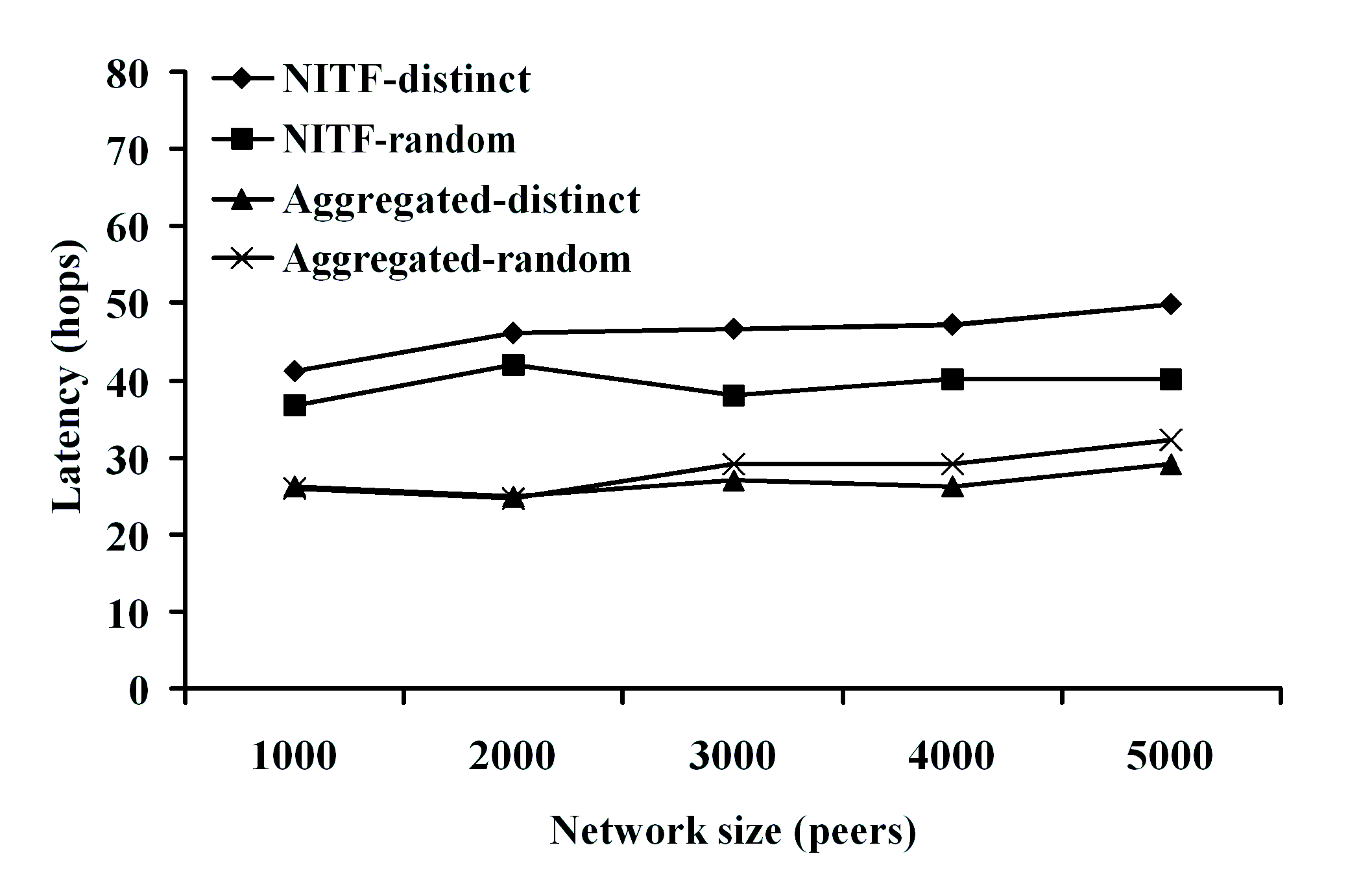
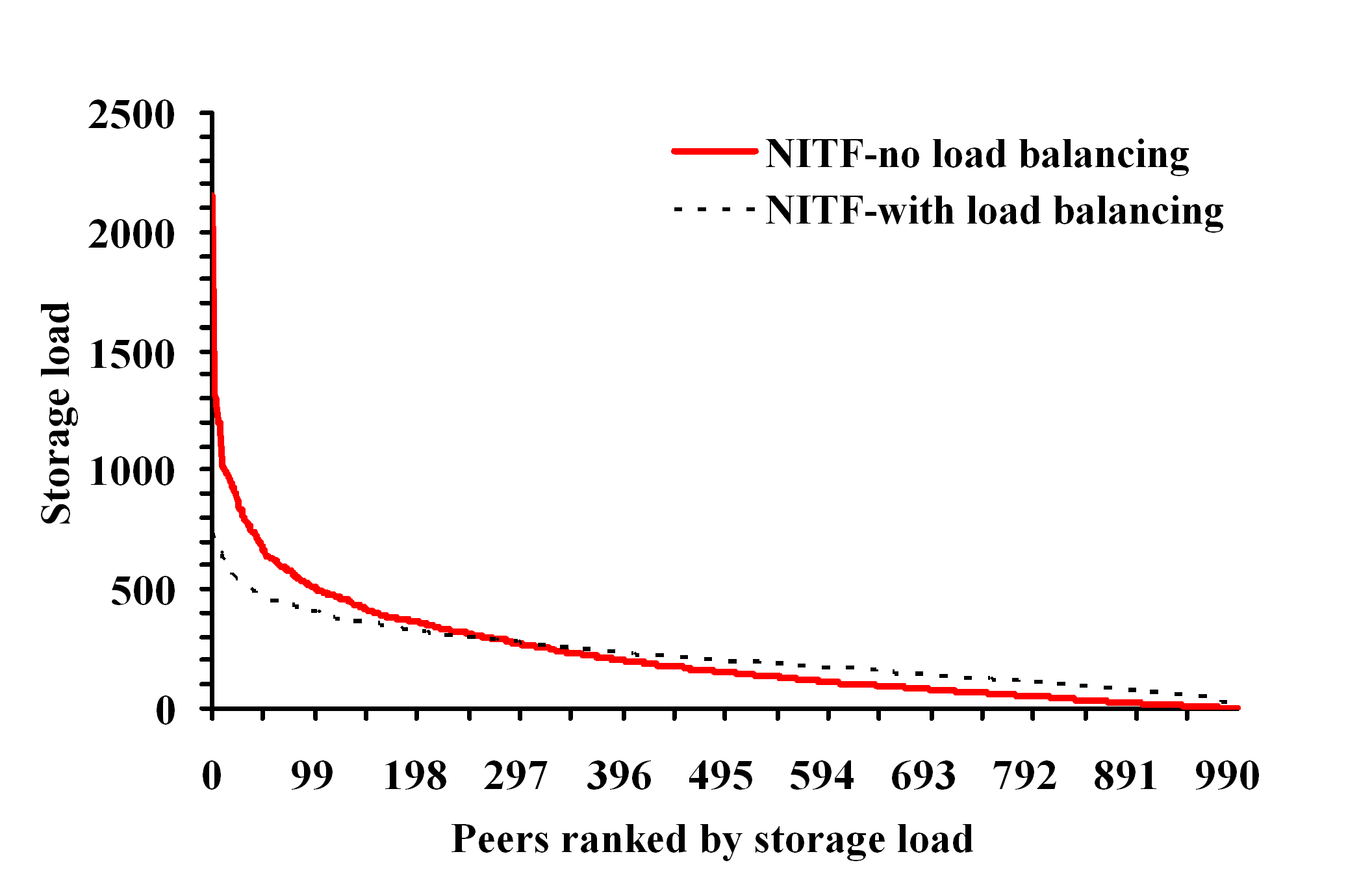
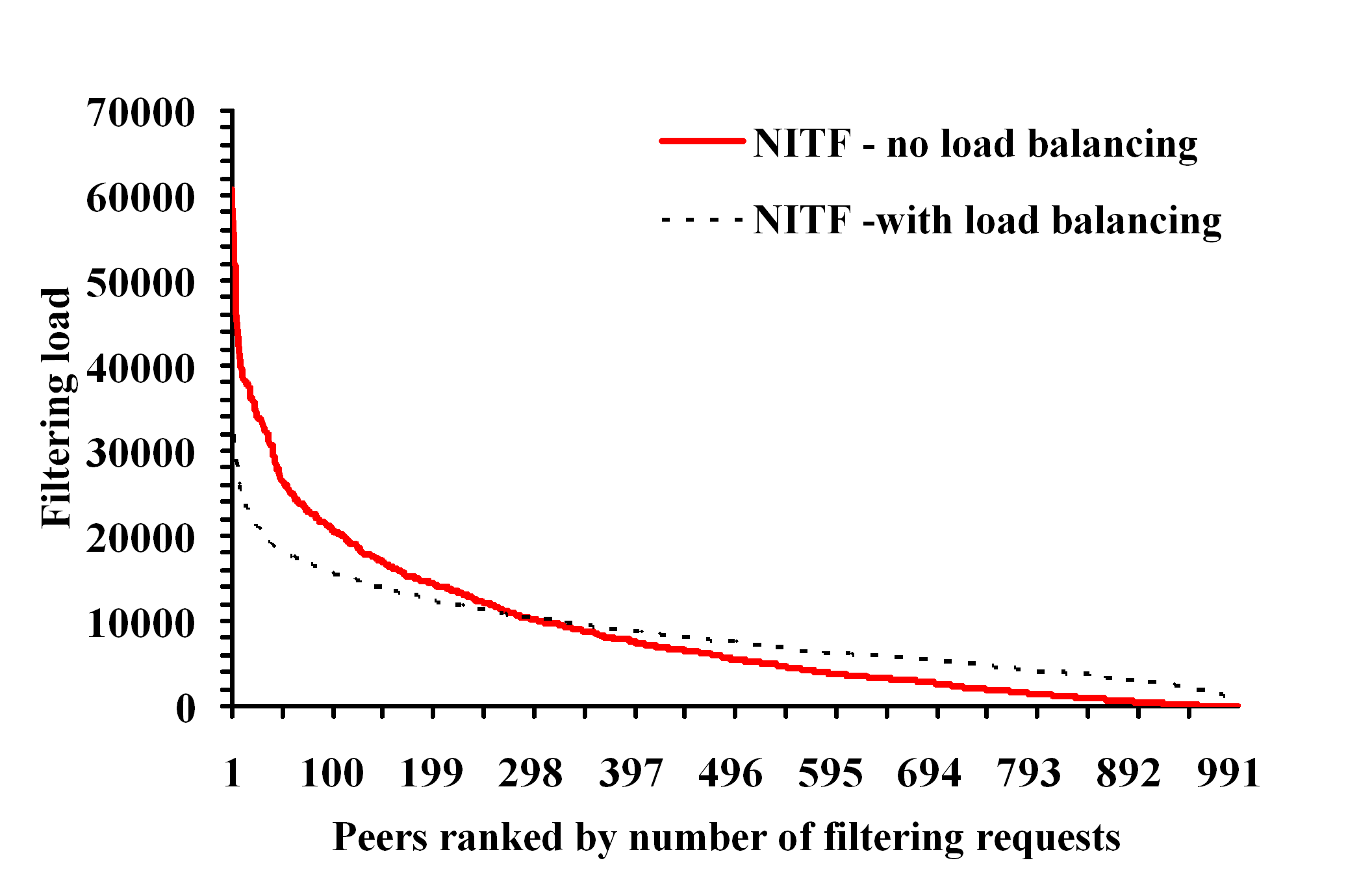
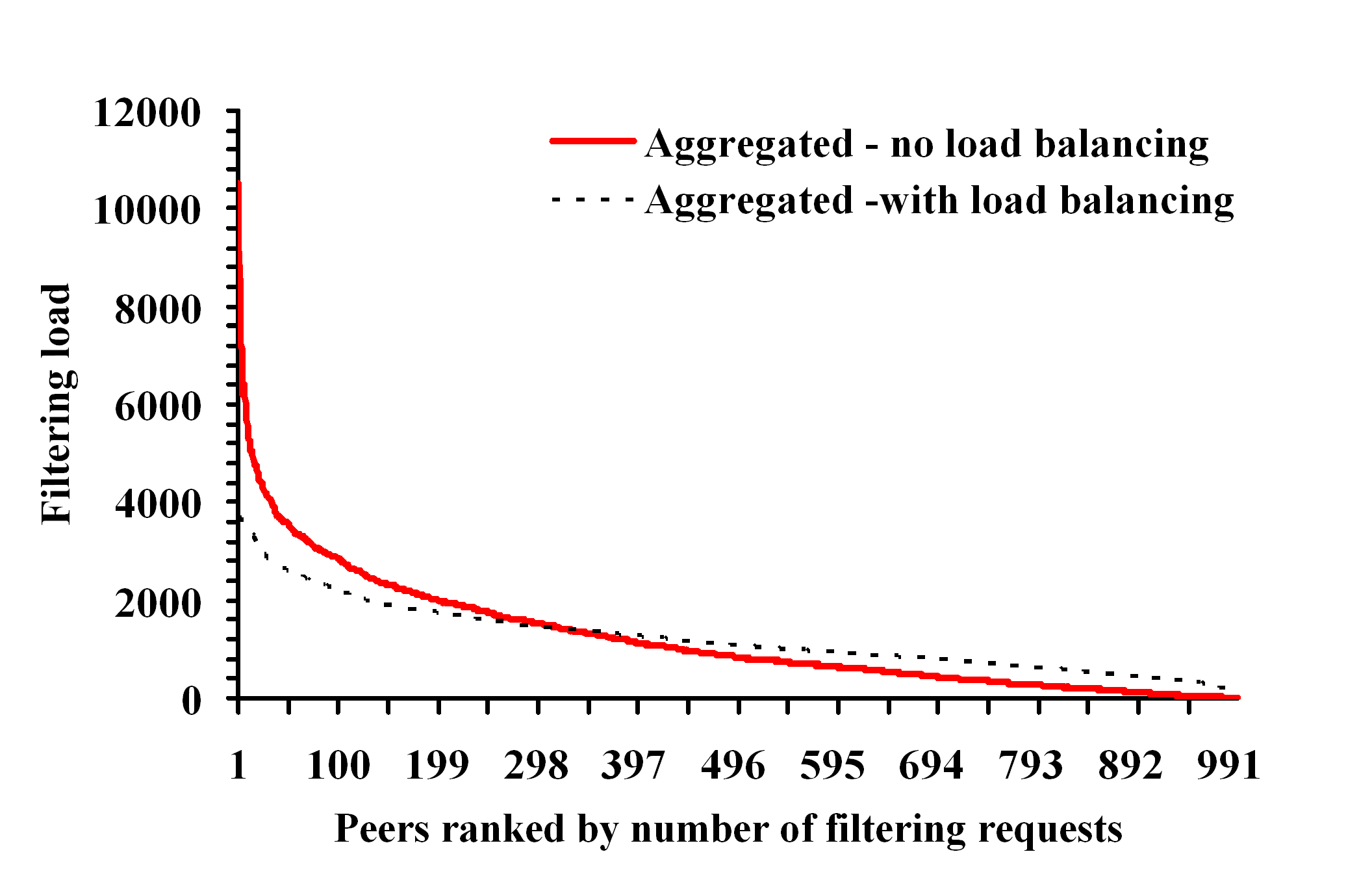
experimentally evaluate our approach and demonstrate that our
algorithms can scale to millions of XPath queries under various
filtering scenarios, and also exhibit very good load balancing
properties.
Categories & Subject Descriptors
H.3.4 [Information Systems]: Systems and Software-
Distributed Systems; H.2.3 [Information Systems]: Languages-Data description languages (DDL), query languages;
F.1.1 [Theory of Computation]: Models of Computation-Automata (e.g., finite, push-down, resource-bounded)