Modern search engines rely on incremental web crawlers [3] to feed content into various indexing and analysis layers, which in turn feed a ranking layer that handles user search queries. The crawling layer has two responsibilities: downloading new pages, and keeping previously-downloaded pages fresh. In this paper we study the latter responsibility, and consider what page revisitation policy a crawler should employ to achieve good freshness.
Good freshness can be guaranteed trivially by simply revisiting all pages very frequently. However, doing so would place unacceptable burden on the crawler and leave few resources for discovering and downloading new pages. Hence we seek revisitation policies that ensure adequate freshness while incurring as little overhead as possible.
Prior work on this problem has focused on two factors when determining how often to revisit each web page:
A third important factor that has thus far been ignored is information longevity: the lifetimes of content fragments that appear and disappear from web pages over time. Information longevity is not strongly correlated with change frequency, as we show in Section 3.2.
It is crucial for a crawler to focus on acquiring longevous (i.e., persistent) content, because ephemeral content such as advertisements or the ``quote of the day'' is invalid before it hits the index. Besides, a search engine typically has little interest in tracking ephemeral content because it generally contributes little to understanding the main topic of a page.
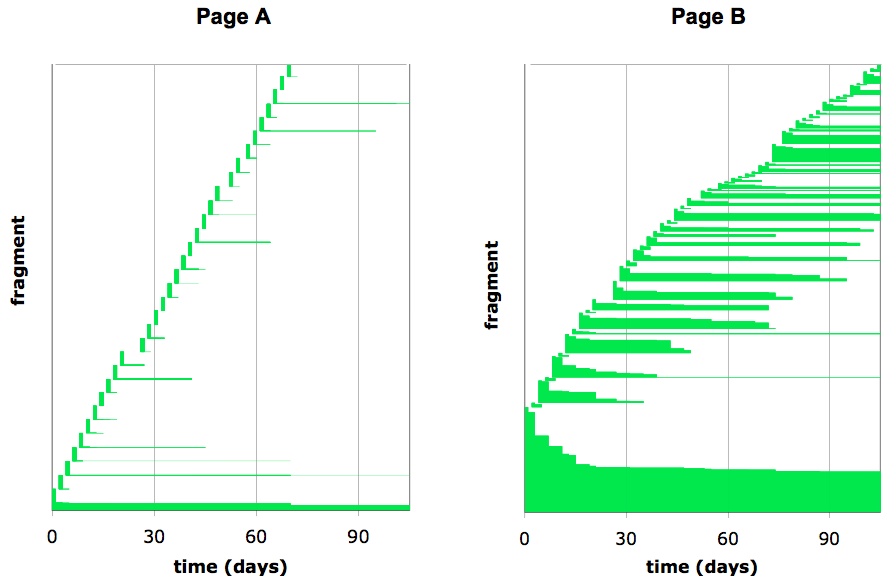
Real web pages differ substantially in the longevity of their content. Figure 1 shows the temporal evolution of two web pages, in terms of the presence or absence of individual content fragments. (The manner in which we divide pages into fragments is not important for the present discussion.) In each graph the horizontal axis plots time, and the vertical axis shows unique fragments, sorted by the order in which they first appear on the page. Each horizontal stripe represents a fragment; the left end-point is the time at which the fragment first appears on the page; the right end-point is the time at which the fragment disappears.
Page A has a small amount of static content, and a large amount of highly volatile content that consists of dynamically generated text and links apparently used to promote other web pages owned by the same organization. Page B contains a mixture of static content, volatile advertisements, and a third kind of content manifest as horizontal stripes roughly 30 to 60 days long. Page B is part of a cooking site that displays a sliding window of recent recipes.
Contrasting Pages A and B, we appreciate the importance of considering the lifetime of information when crafting a page revisitation policy. Pages A and B both undergo frequent updates. However Page A is not worth revisiting often, as most of its updates simply replace old ephemeral information with new ephemeral information that would be pointless for the search engine to index. Page B, on the other hand, is adding information that sticks around for one to two months (i.e., recipes) and might be worthwhile to index, making Page B worth revisiting often. (We estimate the prevalence on the web of pages like A and B in Section 3.3.)
Information longevity has been measured in various ways in previous work [1,8,9]. However we are not aware of any work that considers its role in recrawl effectiveness.