Let
Data reuse and integration is the basic idea behind the Semantic Web effort. However, the extremely large and highly distributed setting of the Web makes reuse and integration a difficult task. Although the basic technologies of the semantic web (URIs to denote things, shared ontologies) are well suited for a distributed environment, data reuse and integration today usually takes place in centralized settings. For example, the book mashup1and DBPedia2 connect various sets of semantic data. Although both services are based on semantic web technologies and use freely available data, integration is done by replicating all data to a single repository and connecting data sources using procedural code.
The semantic web suffers from a lack of user generated content and from a lack of services to kick-start wide adoption. One of the reasons for these deficiencies is a missing mechanism for easy, distributed data reuse and integration: As we are talking about quite large datasets in the examples listed above, already the necessary infrastructure for holding the resulting amounts of data keeps many people from offering such services. In order to encourage people to build new services based on existing data, a more flexible and distributed mechanism is needed.
There are two main approaches to data reuse on the semantic web: replication plus procedural code and rule languages. Procedural code is harder to exchange than declarative rules and its semantics is implicit. Replication leads to problems with
Rule languages such as the Semantic Web Rule Language SWRL [10], N3 [3] and the upcoming Rule Interchange Format RIF [9] allow for defining how to reuse data in a declarative way. However, they work best in a centralized setting, because apart from N3, none of them allows users to specify where the data to reason on comes from and which dataset the result should belong to. Additionally, these languages are unfamiliar for people without a background in logics -- and most people using semantic web technologies now and in the future can be assumed not to have such a background. Finally, they have not been designed to gracefully handle recursion and negation in a dynamic environment like the web. As we will see in our use case, these properties are already desirable for simple scenarios.
We propose Networked Graphs as a declarative mechanism to define RDF graphs both extensionally, by listing statements, and intensionally using views on other graphs. SPARQL and a small syntactic extension to RDF are used to define views. The proposed mechanism is very powerful and flexible, as it allows one to use almost all of the expressiveness of SPARQL CONSTRUCT queries, including negation, and -- when used inside Networked Graphs -- recursive views. Networked Graphs are designed to be evaluated in a distributed setting and are easily exchangeable. Users of Networked Graphs do not need to learn a new rule language, but can use the standard language SPARQL -- which we expect to be widely adopted soon.
In this paper we define a syntactic extension to RDF which allows for expressing views in RDF graphs in a declarative way in section 4. We define the semantics of NGs through an extension of the SPARQL semantics in section 5. We describe a prototypical implementation in section 6 and finally shortly discuss the complexity of reasoning with NGs is in section 7. Foundations and extensions are illustrated using a running example. We start our description in the following Section 2 with a use case from which we derive requirements, and which serves as a running example in the remainder of the paper. We introducw existing formalisms in Section 3. In the following we use ``NG'' to abbreviate ``Networked Graph''.
Mike is project manager of a new semantic web research project. As with most new projects, he needs to build a project website containing information about the people working in the project. We talk about a Semantic Web project, so all information shall be available in RDF. All project members are Semantic Web enthusiasts and provide information about themselves in their personal foaf3files on the web. Mike would like to avoid replicating this information. He also does not want to have to update the project website, whenever one of the members changes her personal information. Mike thinks a view mechanism for RDF would be ideal to extract the information he needs.
Reusing Information. Mike's first task is to build a page containing contact information of all project members. He sets up a graph mikesProject. He defines a view feeding into mikesProject based on the foaf files of the project members. It imports names, e-mail addresses, phone numbers and employers of all people working in the project.
Importing third-party data. After a couple of months, Mike is asked to include all publications done within the project to mikesProject. All project members work full time for the project. Therefore Mike can assume that all their publications done during the lifetime of the project are relevant. He adds a view based on the DBLP RDF mapping4, including all publications by project members listed in mikesProject within the time period of 2007-2009. Whenever anything relevant is newly published, it will be included in the project website automatically.
Negation. Mike thinks, it will be nice, if the project acknowledges all those authors who have contributed to publications done in the project, but who do not work in the project themselves. He sets up a new view, adding acknowledgements to all those authors of papers, which have creators from the project, but where the persons acknowledged are not listed as project members in mikesProject. Mike uses the Semantic Web query language SPARQL, which allows to formalize this rule using negation by failure.
Recursion. Bob works in the project. He finds the information on the project website very useful. As the project is rather small, he assumes he knows everybody in the project. For this reason he adds a view to his foaf file bobFOAF, which creates a foaf:knows relation between Bob and every person listed as a project member in mikesProject. This results in a circular dependency between bobFOAF and mikesProject.
Exchange of NGs. Mandy manages a similar project. Today she is faced with the task of creating a new project website. Mandy likes Mike's website a lot and would like to set up something similar. Usually, her semantic web browser immediately computes all views. She did not even notice that Mike uses them. Today, however, she looks at mikesProject with a text editor and sees all the view definitions. She replaces the datasets of the views such that the foaf files of her own project's members are used. After only five minutes of work she has created a rich project description in graph alicesProject.
We observe the following requirements from the presented use case:
Linking Dataspaces. A new line of research in databases aims at creating and linking dataspaces [6], i.e. heterogeneous spaces of information, such as available in small databases and on PC desktops. While the gist of this work is related to our objectives, they pursue their goals with idiosyncratic mechanisms rather than by standardized languages as we do with our minor extension of RDF and SPARQL towards NGs.
Distributed Rules for Policies. Alves et al. propose a distributed, rule based policy mechanism [2]. Their language extends Prolog in a proprietary way. Using NGs an elegant integration of the policy mechanism with the semantic web could be achieved.
Decentralized Data Integration. DBPedia integrates various datasets, which are available in RDF. Among others, links to the geonames ontology5 and to DBLP are included. An aggregated dataset is published in irregular intervals. This data could directly be integrated using networked graphs, immediately including changes from any of these datasets.
In this section we briefly describe existing foundations of NGs.
RDF is a graph based knowledge representation language. The nodes in a graph are URIs, blank nodes (a kind of existentially quantified variables) or literals. Arcs between the nodes, labeled with URIs, represent their relationships. We simplify the RDF graph model [14] here slightly in order to come up with a more concise formal characterization. Analogous to the SPARQL specification [4] we allow literals as subjects of statements.
[14] defines a model theoretic semantics for RDF graphs and the RDF Schema Language RDFS. RDFS includes, for example, transitivity of class subsumption, the instanceOf relationship and others. We refer the reader to [14] for a detailed description of RDF and the RDF Schema language RDFS.
While the RDF recommendation does not allow referring to whole RDF graphs, named graphs introduced in [11] offer means to group a set of statements in a graph and to refer to this graph using a URI. This way information about the graph can be expressed in RDF using its name as a subject or object:
The following example illustrates the triple structure of RDF and the concept of named graphs using Trig notation6The statements in a named graph are listed in curly brackets, prepended by the name of the graph. Due to space constraints we will use abbreviated URIs without namespaces.
:DBLP {:NGPaper dc:creator :Alice.
:NGPaper dc:creator :Bob. }
:bobFOAF {
:bobFOAF foaf:primaryTopic :Bob.
:Bob foaf:name "Bob"^^xsd:String.
:Bob foaf:currentProject :K-Space.
:K-Space foaf:fundedBy :EU.
:Bob foaf:phone "+49-261-287-2868".}
:MikesProject {
:SemWebProj foaf:name "Networked Graphs".}
SPARQL is a query language for RDF based on graph pattern matching, which is defined in [4]. In this paper we are only interested in SPARQL CONSTRUCT queries. A CONSTRUCT query matches a graph pattern against one or more input graphs. The resulting variable bindings are embedded into a graph template in order to generate new RDF data. To further restrict the bindings produced by pattern matching, filter expressions can be used, for example to check for (in-)equality of variables, datatypes of literals etc.
A SPARQL query is evaluated against a dataset consisting of a set of named graphs (declared using FROM NAMED clauses) and a default graph, which is the union of one or more named graphs (declared using FROM clauses).
A query returning foaf:currentProject triples for all persons with some foaf document in the dataset is shown in example 2. It selects all persons from all foaf files Mike uses to built mikesProject. Additionally, their phone numbers are included, if available.
CONSTRUCT {?member foaf:currentProject ?project.
?member foaf:phone ?phone}
FROM NAMED :bobFOAF FROM NAMED :chrisFOAF FROM NAMED...
WHERE {
GRAPH ?foafFile {
?foafFile foaf:primaryTopic ?member
OPTIONAL { ?member foaf:phone ?phone } } }
SPARQL can be used to model negation by failure using a combination of OPTIONAL graph patterns and the BOUND filter, which checks whether a variable has been bound during graph pattern matching. We will call such a construct in a query bound negation. Example 3 illustrates the use of bound negation to select co-authors of project members, whom Mike wants to thank for contributing to papers. In this query we first find all co-authors of project members. We then try to find an (optional) foaf:currentProject relation between the project and the co-authors. If this fails (i.e. the co-author is not a project member), the variable ?x is left unbound, and the filter expression at the end of the query succeeds. The obtained variable bindings are embedded in the CONSTRUCT template to add an acknowledgement to the co-author7.
CONSTRUCT {:SemWebProject :acknowledges ?author}
FROM NAMED :DBLP FROM NAMED :mikesProject
WHERE {
GRAPH :DBLP {
?paper dc:creator ?author.
?paper dc:creator ?member }.
GRAPH :mikesProject {
?member foaf:currentProject :SemWebProject
OPTIONAL { ?x foaf:currentProject :SemWebProject
FILTER (?x = ?author) }
FILTER (!BOUND(?x)) } }
We propose NGs to fulfil the requirements listed in section 2 by extending the technologies listed in the previous section. To address requirement (1) on expressing RDF graphs by extensional and intensional means, we extend RDF with a SPARQL based view mechanism. To support exchangeability and backwards compatibility (requirements 4 and 5), we define a syntax based on named graphs. By this extension it becomes possible to define the meaning of such a network of graphs by the way they reference each other. To deal with negation and cycles (requirements 2 and 3), we adapt a suitable semantics from logic programming in section 5 and explain how it can be computed in a distributed setting in section 6.
In this section we start by defining NGs using an abstract syntax, before we introduce the RDF and SPARQL based syntax for NGs.
In the previous section we have seen how SPARQL can be used to express a single view in a dataset. What is still missing is a link between the view definition and the graph, which shall include the view. This link is given be NG s:
We define a function deref to access the contents of a NG given a NG definition. deref carries out dereferencing of NGs as a logical operation, i.e. given a NG it computes the content of the NG. This logical operation is opposed to dereferencing as an addressing operation, i.e. given a URI, accessing the corresponding file or SPARQL endpoint. In contrast to named graphs, NGs are not necessarily listed in a single file or at a single endpoint, as parts of them are inferred. In Section 5 we will describe, how deref can be computed for a set of NGs.
Then deref is a function mapping from networked graphs into a set of statements, i.e. a graph:
deref
![]() deref
deref![]() deref
deref![]()
From these definitions it is clear, that named graphs are a
special case of NG s with
![]() . In our use case
scenario, the graph mikesProject
could be formalized as follows:
. In our use case
scenario, the graph mikesProject
could be formalized as follows:
mikesProject = (:mikesProject,
{(:SemWebProj foaf:name "Networked Graphs")},
[bobFOAF, chrisFOAF, DBLP,
mikesProject], ![]() ),
),
with
![]()
{(:Bob foaf:currentProject :SemWebProject),
(:Bob foaf:phone "+49-261-287-2868"),
(:Chris foaf:currentProject :SemWebProject),
(:SemWebProject :acknowledges :Alice)}
For reasons of simplicity, we will use the name of a NG interchangeably with the NG itself. From the context it will be clear, whether the name or the NG is meant.
We now provide an RDF syntax for NGs based on named graphs for the extensional definitions and SPARQL for the intensional definitions.
n g:definedBy <query>.8
where <query> is a literal containing a
CONSTRUCT query. The datatype of <query> is
g:query. We call <query> a subquery of
![]() . We call such a statement a view definition
statement. In general, a named graph may contain a number
. We call such a statement a view definition
statement. In general, a named graph may contain a number
![]() of such view definition statements. The overall
view is then defined by
of such view definition statements. The overall
view is then defined by
![]() ,
where
,
where ![]() is the evaluation function of the
is the evaluation function of the ![]() -th subquery.
-th subquery.
definedBy statements are intended to carry two meanings. First, there is the extensional meaning that the statements exists. Second, there is the intensional meaning, i.e. the evaluation of the view it defines. The second meaning will only be incurred, if the graph in which a definedBy statement occurs is identical with the subject of this statement. Existing machinery for working with named graphs can be used for serialization and exchange of NGs. A non NG aware repository can still interpret the extensionally listed statements in a NG, providing upwards compatibility.
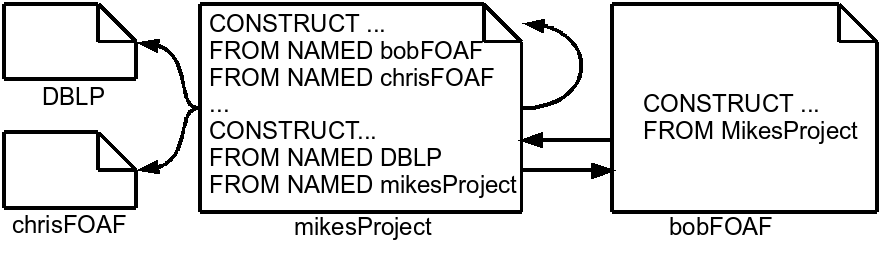
Using this syntax, the definitions of bobFOAF and mikesProject are listed in example 5. In both cases, a named graph holds the extensions introduced in example 1 and the view definitions. In bobFOAF, foaf:knows relations are created from Bob to all project members listed in mikesProject, except for Bob himself. mikesProject contains view definitions encoded in three queries. The first one adds project members and their phone numbers, if available. The second one analogously imports publications from DBLP, so we only sketch it here. The third one adds acknowledgements to all authors listed in DBLP, such that one of their publications has an author, who is listed as project member in mikesProject, but the acknowledged person herself is not a project member, as explained in example 3.
:bobFOAF {
:bobFOAF foaf:primaryTopic :Bob.
:Bob foaf:name "Bob"^^xsd:String.
:Bob foaf:currentProject :K-Space.
:K-Space foaf:fundedBy :EU.
:Bob foaf:phone "+49-261-287-2868".
:bobFOAF g:definedBy
"CONSTRUCT {:Bob foaf:knows ?person}
FROM :mikesProject
WHERE { ?person foaf:currentProject :SemWebProject
FILTER (?person != :Bob) }"^^g:query.
}
:mikesProject {
:SemWebProj foaf:name "Networked Graphs".
:mikesProject g:definedBy
"CONSTRUCT {?member foaf:currentProject ?project.
?member foaf:phone ?phone}
FROM NAMED :bobFOAF FROM NAMED :chrisFOAF ...
WHERE { GRAPH ?foafFile {
?foafFile foaf:primaryTopic ?member
OPTIONAL {?member foaf:phone ?phone}}}"^^g:query.
:mikesProject g:definedBy
"CONSTRUCT {?paper dc:creator ?author}..."^^g:query.
:mikesProject g:definedBy
"CONSTRUCT {:SemWebProject :acknowledges ?author}
FROM NAMED :DBLP FROM NAMED :mikesProject
WHERE {
GRAPH :DBLP { ?paper dc:creator ?author.
?paper dc:creator ?member}.
GRAPH :mikesProject {
?member foaf:currentProject :SemWebProject
OPTIONAL { ?x foaf:currentProject :SemWebProject
FILTER (?x = ?author) }
FILTER (!BOUND(?x)) } }"^^g:query.
}
Figure 1 illustrates the interdependencies of NGs resulting from the definitions in example 5. We call such a set of interdependent graphs an interdependence set.
We now revisit the requirements from our use case to discuss requirements on the NGs semantics. Afterwards we give an overview of the semantics. A detailed definition is given in the appendix. For the understanding of the detailed semantics, some knowledge of the SPARQL algebra [4] and of the well founded semantics for logic programs [20] is required. Unfortunately we do not have enough space to repeat the these foundations in detail here.
As we have pointed out when describing the use case, we envision NGs to be a mechanism used by a broad range of agents on the semantic web to recombine RDF data. In this environment, it is not possible to pose restrictions on the use of NGs (requirement 2), for example to ensure hierarchical dependencies between NGs or stratified use of negation (i.e. no view using negation directly or indirectly depends on itself).
Cyclic Definitions of Networked Graphs. A scenario that may lead to problems with naive interpretations is given when you assume that Mikes assistant Anna persuades all acknowledged authors to join the project. She adds a view to mikesProject saying that everybody acknowledged has :SemWebProject as a foaf:currentProject. Now obviously nothing can be inferred about acknowledged authors anymore, because they are only acknowledged if they are not members of the project. However, we still want to have contact information and literature of everybody else available on the website, as they are not affected by this contradiction. The semantics of NGs must be able to handle such mutual dependencies via negated premises.
SPARQL, Rules and Logic Programs.
Networked
Graphs are quite similar to logic programs. In fact we show how
SPARQL can be mapped to acyclic Datalog with negation in
[17].
Independently, Polleres defines a mapping to logic programs under
the stable model semantics [16]. We define
the semantics of NGs analogously to a fixpoint semantics for
logic programs. From a high level point of view we treat SPARQL
CONSTRUCT queries as rules with negation. While the encapsulation
of SPARQL algebra expressions into a fixpoint semantics may seem
a bit complicated at first, it has two clear advantages: First,
it allows for using existing SPARQL endpoints. Second, NGs can
automatically benefit from future extensions of SPARQL such as
aggregates or user defined filter functions.
RDF Schema. SPARQL defines entailment regimes under which a query can be evaluated. The standard entailment regime is simple RDF entailment. However, more complex regimes like RDFS are possible, the only requirement being monotonicity of the entailment regime. Using a more complex entailment regime, NGs can be evaluated taking RDFS into account, without additional extensions to NG s. (Note that NGs are expressive enough to alternatively model the RDFS inference rules as view definitions.) Sirin and Parsia propose an entailment regime for a subset of SPARQL, which can be used to query OWL ontologies taking into account OWL DL semantics [5]. Using such an entailment regime could even bring the power of OWL to a subset of NG s. Interaction with OWL, however, would need a detailed investigation of the resulting combined language. In the following we assume a basic RDF entailment regime.
We address the requirements on the semantics, especially regarding reasoning in the presence of contradictions, by adapting the well founded semantics (WFS) for logic programs [20] to NGs. In this section we describe the core idea of the WFS. Details are given in the appendix.
Fixpoint Model for Well-founded
Semantics. The WFS is based on a three valued logic with
truth values of true, false and
unknown. It assigns truth values of true and false to as
many facts as possible. For facts, where such an assignment is
not possible, the truth value assigned is unknown. This is the
case for non-stratifiable negation as sketched above. The WFS
treats true and false facts symmetrically, and is defined using
the fixpoint of a direct consequence operator ![]() ,
which we briefly explain in the following paragraphs.
,
which we briefly explain in the following paragraphs.
The WFS for NGs assumes all extensionally listed statements
and everything we can follow from these statements without using
bound negation to be true and by assuming all statements
in the so called greatest unfounded
set to be false. To explain the unfounded set, we
need the notion of ground instantiated
views. A view is ground instantiated by replacing every
variable in the view with an element of the set of RDF Resources
![]() . Hence, the statement patterns in a ground
instantiated view do not contain variables any more.
. Hence, the statement patterns in a ground
instantiated view do not contain variables any more.
We say an optional statement used in bound negation like
(?x foaf:currentProject :SemWebProject) in example
3 is matched negatively. All other statements are
matched positively. A statement ![]() is
in an unfounded set
is
in an unfounded set ![]() , if
for all ground instantiated views
, if
for all ground instantiated views ![]() with
with
![]() in the CONSTRUCT pattern one of the following
holds: (1) All negatively matched statements in
in the CONSTRUCT pattern one of the following
holds: (1) All negatively matched statements in ![]() are
known to be true or (2) Some positively matched statement in
are
known to be true or (2) Some positively matched statement in
![]() is known to be false or (3) Some positively
matched statement in
is known to be false or (3) Some positively
matched statement in ![]() is
in
is
in ![]() . The greatest unfounded set is the union of all
unfounded sets.
. The greatest unfounded set is the union of all
unfounded sets.
The third condition applies to mutually dependent ground instantiated views, where none of the views can be established to be true or false first.
The sets of true and false statements are extended iteratively
by computing the direct consequences of the known true and false
statements until a fixpoint is reached. The direct true
consequences are statements in the CONSTRUCT patterns of ground
instantiated views, which match the
known true and false statements from the previous iteration. A
new unfounded set based on the knowledge from the previous
iteration is determined. All statements in the new unfounded set
are direct false consequences.
Statements that are not assigned a value of true or false,
when the fixpoint is reached, are assigned a truth value of
unknown statements. We define the semantics of a NG ![]() ,
deref
,
deref![]() ,
as the set of true statements in the graph when reaching the
fixpoint.
,
as the set of true statements in the graph when reaching the
fixpoint.
Example. In our example, after
Anna has added her new view, all ground instantiations of this
new view together with the view defining the acknowledgements
form an unfounded set: every statement of the form
(:semWebProject :acknowledges sbd) negatively depends on
a statement of the form (sbd foaf:currentProject
:SemWebProject),
which in turn depends on the first statement. Hence, no
statements about acknowledged authors are inferred. However, all
views, which are not directly affected, are not influenced by the
contradiction, because the statements they generate are not part
of an unfounded set.
Procedural Semantics. Obviously it is difficult to work with all possible ground instantiated statements and to guess an unfounded set, because of combinatorial explosion and non-determinism. A procedural semantics is available, however, which we shortly explain in the next section.
We have implemented a NG reasoner as an extension for the
Sesame 2 RDF repository. Implementation, public prototype and
test data are available at
http://isweb.uni-koblenz.de/Research/NetworkedGraphs.
The implementation uses a variation of the alternating fixpoint algorithm for computing the WFS [7], which does not require to guess an unfounded set. The algorithm is initiated with true statements in an interdependence set. It then alternates between an overestimation of the set of true, inferred statements and an underestimation of this set. Eventually, this alternation converges to the set of true statements in the interdependency set.
In some more details, the procedure starts with the true
statements, which are extensionally listed, or which can be
derived from views, which do not use negation. We call this
underestimate ![]() .
Statements in
.
Statements in ![]() are known to be true.
are known to be true. ![]() is
used to compute an overestimate
is
used to compute an overestimate ![]() by
evaluating all views against this set of true statements. The
result will be an overestimate, because
by
evaluating all views against this set of true statements. The
result will be an overestimate, because ![]() was still incomplete and therefore bound negation will succeed in
too many cases.
was still incomplete and therefore bound negation will succeed in
too many cases. ![]() represents the set of potentially
true statements. We do not know for every statement in
represents the set of potentially
true statements. We do not know for every statement in
![]() , whether it really is true, but at least it is
not definitely false. Now we compute a new underestimate, using
, whether it really is true, but at least it is
not definitely false. Now we compute a new underestimate, using
![]() to match negatively matched statements and
to match negatively matched statements and
![]() to match all positively matched statements. The
result
to match all positively matched statements. The
result ![]() is an underestimate of true statements that
is larger than
is an underestimate of true statements that
is larger than ![]() .
.
When after some iterations we come up with the same under- and overestimates as in the previous iteration, a fixpoint has been reached. The underestimate then equals the true statements under the WFS, i.e. it represents the semantics of the interdependence set.
The algorithm is combined with tabling to reduce the amount of redundant work. Tabling means we save intermediary results during the iterative computation, instead of recomputing them when needed. Apart from saving redundant work, this also reduces network traffic during distributed evaluation. Additionally, we apply heuristics to filter out irrelevant parts of interdependence sets. NGs evaluation takes place at query time in the current prototype.
Every view, together with its table of interim results and some status information used for the detection of cycles, is represented as a single 'QueryNode' object. This allows to distribute NG reasoning by distributing QueryNodes to the machines holding the relevant graphs. The communication between QueryNodes is done using the existing SPARQL protocol, with small extensions for control data. The extensions are threefold:
First, when involving multiple endpoints in NG evaluation, we need to detect and avoid cycles. Hence, we extend the SPARQL query protocol with a list of queryIDs. Whenever a QueryNode forwards a query to evaluate some view, it generates a new queryID and appends it to the list. Upon receiving a query, a QueryNode compares the list of queryIDs in the query message with the list of the queryIDs it has generated itself. If a cycle is detected, subsequent queries are not forwarded to other peers. The received query is only evaluated on local data and the result is returned. Using this extension, an iteration of the alternating fixpoint procedure is started by a single QueryNode and triggered on other nodes in a tree shaped hierarchy. After every iteration, every QueryNode updates its table of results. Only new results are returned to other nodes.
Second, through indirect dependencies it may happen that the same QueryNode is triggered twice in the same iteration. To avoid duplicate work or errors in the tables, each queryID is augmented by an iteration number. If an already computed combination of queryID and iteration number is received, the query is answered from the local table.
Finally, the query result message is extended with a flag signalling that the answering node considers the evaluation of its view done - either because all views it depends on are also done, or because it is the root of a subtree of the QueryNode network, for which a fixpoint has been reached. This last extension is only used to improve performance, as it can save the last iteration of the alternating fixpoint algorithm. The fixpoint could also be detected by the node which started the evaluation.
The protocol is defined as an extension to the SPARQL protocol specification9 and available from the implementation webpage. As the mechanism is based on existing standards, it allows the usage of existing SPARQL endpoints when defining NGs. When dealing with non NG aware repositories, one may fall back to standard SPARQL.
We briefly investigate the data complexity of NG evaluation. The data complexity is defined as the complexity of computing a model for a variable extensional knowledge base given a fixed query. Data complexity is of particular interest here, as usually the view definitions are short compared to the knowledge base. Further we expect view definitions to be rather stable, while the extensionally defined statements might frequently change.
If blank nodes are created in the CONSTRUCT patterns of views and these views are used recursively, evaluating NGs becomes undecidable in general. In this case, we could have infinitely many ground instances of statement patterns. For this reason we limit the discussion to NGs without blank node creation.
If negation is not used in recursive view definitions, we can give a tighter bound:
The combined complexity is the complexity of computing a model for both variable queries and knowledge bases.
All proofs are based on mappings to fragments of logic programming and their well known complexity. Proofs for theorems 1 and 2 and can be found in [18]. The proof of theorem 3 is derived from the facts that NGs can be mapped to datalog with well founded negation [18], which has EXPTIME combined complexity (implicit in [20]). NGs creating blank nodes correspond to logic programs with function symbols, which are undecidable in general under the WFS.
Related work comes from several areas, especially from rules and views for the semantic web.
OWL Contextualization. For the Web
Ontology Language OWL, which is based on RDF, declarative
approaches for import and contextualisaton have been
proposed:
owl:imports is a mechanism for OWL which includes a
whole OWL file in another one. It is
a rather coarse mechanism, not flexible enough for the use case
presented here. C-OWL [13] is an extension
of OWL with local contexts connected with bridge rules. C-OWL
aims at translations between local contexts, not at reuse of
RDF/OWL data.
Rules to deal with (variations of) named graphs. Approaches for dealing with RDF graphs with either a declarative or a procedural semantics include the following:
Stoermer et al. use named graphs plus semantic extensions of RDF to implement a system using modal logic for statements in RDF graphs [8]. The RDF semantics is extended, such that statements are only true in the context of a graph called a context. Between these graphs compatibility relations can be defined and inferred. The focus lies on describing relationships among graphs. Reuse of RDF data, for example by importing statements, is not possible.
The NEPOMUK Representation Language NRL [19] is used in the context of a Social Semantic Desktop to allow for a kind of views and to apply various different semantics to RDF graphs. NRL allows for various ways to specify ``views'', which are defined with a procedural semantics in contrast to the declarative semantics of NGs. Applied in a heterogeneous and distributed web environment, we expect problems with this procedural semantics, because implications will become hard to understand.
N3Logic [3] is a rule language built around RDF. Its expressive power is comparable to NGs for positive rules. Only a weaker form of negation is supported by N3Logic. N3Logic defines several builtins, e.g. cryptographic functions, which are not available in NGs, but could be modeled using user defined filter functions in SPARQL. An advantage of NGs in our opinion is its foundation on SPARQL -- both to save users the effort of learning a new language and to directly benefit from SPARQL implementations and extensions.
Views. [21] and [12] propose declarative view mechanisms for RDF. They can be used to define ``virtual'' classes, properties and instances based on graph patterns. RDFS semantics is employed to ensure that necessary class relations are also included in the view. The purpose is to provide a view to a graph using a different ontology rather than defining graph contents based on other graphs. These classical views are not oriented towards reuse and exchange of views across the borders of single RDF repositories.
Semantic Web Pipes10 can be used to define RDF documents as views on other documents. An XML syntax is used and cyclic dependencies are not supported. Semantic Web Pipes are designed rather as a web service than as a declarative mechanism.
ActiveXML Abiteboul et al.
describe ActiveXML documents [1], which
represent a concept very similar to NGs, but based on XML.
ActiveXML documents may contain intensional subtrees defined
through web service calls or XPath queries. The semantics of
ActiveXML documents is also defined using a fixpoint, but unlike
NGs, ActiveXML documents are infinite in general. In contrast to
ActiveXML, NGs support a powerful kind of negation. While NGs can
support various entailment regimes through the use of
SPARQL, ActiveXML documents have weaker semantics based on
XML.
We have introduced Networked Graphs as a means for describing RDF graphs that are partially derived from other graphs using a declarative view mechanism. We base Networked Graphs on work on SPARQL and Named Graphs. Extensions allow for recursive view definitions, i.e. a kind of rules, and easy exchange of self describing Networked Graphs. Thus, Networked Graphs allow for defining, exchanging and executing SPARQL rules, SPARQL views and RDF data integration in a decentralized fashion. We have shown that the complexity of our extension allows for use at web scale, especially if negation is used carefully. Thus, we propose a mechanism for easy information reuse and recombination and have fulfilled the requirements derived from our running use case -- which is just one of the many cases that will benefit from dynamic networking between RDF graphs.
This research was supported by the European Commission under contract FP6-027026, Knowledge Space of Semantic Inference for Automatic Annotation and Retrieval of Multimedia Content - K-Space and contract IST-2006-027595, Lifecycle Support for Networked Ontologies - NeOn. The expressed content is the view of the authors but not necessarily the view of the K-Space and NeOn projects.
[1] S. Abiteboul, O. Benjelloun, and T. Milo. Positive Active XML. In Proc. of PODS-2004, 2004.
[2] M. Alves, C. V. Damásio, W. Nejdl, and D. Olmedilla. A Distributed Tabling Algorithm for Rule Based Policy Systems. In Proc. of POLICY-2006, 2006.
[3] T. Berners-Lee, D. Connolly, L. Kagal, Y. Scharf, and J. Hendler. N3logic: A logic for the web. J. of Theory and Practice of Logic Programming (TPLP), Special Issue on Logic Programming and the Web, 2007.
[4] E. Prud'hommeaux, A. Seaborne (eds.). SPARQL Query Language for RDF. http://www.w3.org/TR/rdf-sparql-query/, 2007.
[5] E. Sirin and B. Parsia. SPARQL-DL: SPARQL Query for OWL-DL. In Proc. of OWLED 2007, 2007.
[6] M. J. Franklin, A. Y. Halevy, and D. Maier. From Databases to Dataspaces: A new Abstraction for Information Management. SIGMOD Record, 34(4), 2005.
[7] A. V. Gelder. The alternating fixpoint of logic programs with negation. In Proc. of ACM SIGACT-SIGMOD-SIGART-1989, 1989.
[8] H. Stoermer et al. RDF and Contexts: Use of SPARQL and Named Graphs to Achieve Contextualization. In Proc. of 2006 Jena User Conference, 2006.
[9] Harold Boley and Michael Kifer (eds.). RIF Core Design. http://www.w3.org/TR/rif-core/, 2007.
[10] I. Horrocks et al. SWRL: A Semantic Web Rule Language Combining OWL and RuleML. http://www.w3.org/Submission/SWRL/, 2004.
[11] J. Carroll et al. Named Graphs, Provenance and Trust. In Proc of WWW-2005, 2005.
[12] A. Magkanaraki, V. Tannen, V. Christophides, and D. Plexousakis. Viewing the semantic web through RVL lenses. J. Web Semantics, 1(4), 2004.
[13] P. Bouquet et al. Contextualizing Ontologies. J. of Web Semantics, 1(4), 2004.
[14] P. Hayes (ed.). Rdf semantics. http://www.w3.org/TR/rdf-mt/, 2004.
[15] J. Pérez, M. Arenas, and C. Gutierrez. Semantics and Complexity of SPARQL. In Proc. of ISWC-2006, 2006.
[16] A. Polleres. From SPARQL to rules (and back). In Proc. of WWW-2007, 2007.
[17] S. Schenk. A SPARQL Semantics Based on Datalog. In Proc. of KI2007, 2007.
[18]
S. Schenk and S. Staab.
Networked RDF Graphs.
Technical report, 2007.
http://uni-koblenz.de/ ![]() sschenk/publications/2007/ngtr.pdf .
sschenk/publications/2007/ngtr.pdf .
[19] M. Sintek, L. van Elst, S. Scerri, and S. Handschuh. Distributed Knowledge Representation on the Social Semantic Desktop: Named Graphs, Views and Roles in NRL. In Proc. of ESWC-2007, 2007.
[20] A. van Gelder, K. Ross, and J. S. Schlipf. The Well-Founded Semantics for General Logic Programs. J. of the ACM, 38(3), 1991.
[21] R. Volz, D. Oberle, and R. Studer. Implementing Views for Light-Weight Web Ontologies. In 7th International Database Engineering and Applications Symposium. IEEE, 2003.
We limit our definitions here to well defined graph patterns as defined in [15]. Graph patterns, which are not well defined introduce another kind of non monotonicity apart from bound negation, which would complicate the following definitions.
Further, we forbid the use of result modifiers: ORDER does not make sense as the result of a CONSTRUCT query is a graph and as such a set. When LIMIT and OFFSET are used to retrieve only a slice of the query results, the semantics of a query may become unclear, as the result becomes implementation specific.
We start by defining necessary data structures. The semantics is defined on well founded graphs, which consist of positive and negative statements. Note that we only need this construct to define the semantics. We do not need to express it in RDF. Definitions 7 and 8 adjust definitions from [4]. Definitions 11 and 12 extend them to sets of NGs.
Table 1: Data Structures and Auxiliary Functions
| Data Structures | |
| The set of all URIs | |
| The set of all URIs, blank bodes and RDF literals | |
| The set of all SPARQL variables | |
|
Polarized statement, a quadruple
of the form |
|
| Well founded graph, a set of polarized statements | |
| A well formed SPARQL query | |
| Dataset, a set of the form | |
|
|
|
| Set of interdependent graphs | |
| Auxiliary Functions | |
|
|
|
|
|
|
| dataset of a query | |
| negation of a dataset | |
|
|
view dependency |
|
The set of datasets of the views
in |
|
A well founded graph
![]() is a set of polarized statements.
is a set of polarized statements.
We say the positive subgraph
![]() of
of ![]() is the set
is the set
![]() .
.
We say the negative subgraph
![]() of
of ![]() is the set
is the set
![]() .
.
![]() and
and ![]() are disjunct.
are disjunct.
The RDF interpretation of a well founded graph
![]() is
is ![]() . The well founded graph of an RDF graph
. The well founded graph of an RDF graph
![]() is the set
is the set
![]() .
.
Definition 7 extends to named graphs
and Networked
Graphs.
We determine dependencies of views based on the datasets of SPARQL queries.
![]() is
called the default graph of the dataset, defined using FROM.
is
called the default graph of the dataset, defined using FROM.
![]() are called named graphs, defined using
FROM NAMED. Let
are called named graphs, defined using
FROM NAMED. Let ![]() be
a SPARQL query, then dSet
be
a SPARQL query, then dSet![]() is the dataset defined in
is the dataset defined in ![]()
We will use negation and union of datasets.
If ![]() (or
(or ![]() ) then
) then
![]() (or
(or
![]() respectively) such that for all
respectively) such that for all
![]()
Iff
![]() then
then
![]() and
and
iff
![]() then
then
![]() .
.
To evaluate a NG ![]() we
must take into account all graphs, which
we
must take into account all graphs, which ![]() depends upon.
depends upon.
An interdependence set
![]() is a set of NGs, such that for all view
definitions
is a set of NGs, such that for all view
definitions ![]() and
and ![]() the following holds: If
the following holds: If ![]() is a view definition in graph
is a view definition in graph ![]() and
and ![]() and dependsOn(
and dependsOn(![]() ,
, ![]() ), then all
), then all ![]() dSet
dSet![]() are also in
are also in ![]() .
.
Figure 1 in section 4 illustrates the interdependence set containing mikesProject. We refer to all datasets involved in evaluating the semantics of an interdependence set as the dataset of an interdependence set.
The dataset of the interdependence set shown in figure
1 is ![]() :bobFOAF
:bobFOAF![]() bobFOAF
bobFOAF![]()
![]() :chrisFOAF
:chrisFOAF![]() chrisFOAF
chrisFOAF![]()
![]() :mikesProject
:mikesProject![]() mikesProject
mikesProject![]()
![]() :DBLP
:DBLP![]() DBLP
DBLP![]()
![]() mikesProject
mikesProject![]()
We need a small change to the SPARQL semantics in order to treat negation symmetrically, by explicitly negating statements instead of using negation by failure. The following definitions 13 - 15 are taken from [4] and extended to well founded graphs.
The SPARQL specification [4] defines a
function eval(D, GP) as the
evaluation of a graph pattern GP with
respect to a dataset ![]() .
Basically GP is the graph pattern of
a view and
.
Basically GP is the graph pattern of
a view and ![]() is the dataset defined in the view. The range
of eval is a solution sequence
is the dataset defined in the view. The range
of eval is a solution sequence
A solution sequence is a list of solution mappings.
Let ![]() be
a SPARQL query and
be
a SPARQL query and ![]() a solution mapping.
a solution mapping. ![]() is the query obtained by replacing every
variable
is the query obtained by replacing every
variable ![]() in
in ![]() by
by
![]() , if
, if ![]() is defined. We say
is defined. We say ![]() is complete for
is complete for ![]() , if it is defined for all variables of
, if it is defined for all variables of
![]() . Analogously, we define GP
. Analogously, we define GP![]() as the RDF graph obtained by substituting
every variable
as the RDF graph obtained by substituting
every variable ![]() in a graph pattern GP by
in a graph pattern GP by ![]() .
.
The solution of a CONSTRUCT query is the set of statements obtained by instantiating the CONSTRUCT pattern using the solution mappings computed by eval. eval is defined for every operator in the SPARQL algebra. It is defined by recursively applying it to its parameters and using join and select operations on the results. We do not discuss in detail how eval is defined, but simply use it as the operator for the evaluation of a single view in a single iteration in the following. However, we need to slightly change the definition of basic graph pattern matching in order to use it with well founded graphs. The operator which matches statement patterns against the dataset is eval(G, BGP), where BGP is a basic graph pattern consisting only of joins of statement patterns and G is a single RDF graph. In contrast to the other operators, basic graph pattern matching is directly evaluated without subsequent calls of eval -- here the actual matching against the dataset takes place.
We say a statement pattern ![]() enclosed in an OPTIONAL pattern
enclosed in an OPTIONAL pattern ![]() of a SPARQL graph pattern
of a SPARQL graph pattern ![]() in
a query
in
a query ![]() is
matched negatively in
is
matched negatively in ![]() , if the following hold:
, if the following hold:
We say that a statement pattern is matched positively, if it is not matched negatively.
The notion of a negatively matched statement pattern formalizes bound negation, introduced in section 3. In example 3, (?x foaf:currentProject :SemWebProject) is matched negatively, all other statement patterns are matched positively. We redefine basic graph pattern matching, such that negative statements are matched instead of using negation as failure, hence treating negation symmetrically. Negative statements are indirectly introduced in NGs evaluation by negating the largest unfounded set, as we will see below.
Let ![]() be a basic graph pattern in a query
be a basic graph pattern in a query ![]() and
and ![]() be a well founded graph. Let posBGP
(negBGP) be the basic graph pattern
containing exactly the positively (negatively) matched
statement patterns in
be a well founded graph. Let posBGP
(negBGP) be the basic graph pattern
containing exactly the positively (negatively) matched
statement patterns in ![]() .
.
![]() is a solution sequence.
is a solution sequence.
![]() is a solution in
is a solution in
![]() , if it is complete for
, if it is complete for
![]() and
and
This definition of basic graph pattern matching treats positively matched statement patterns as in [4]. The result is empty, if negatively matched statements are known to be negative. For single SPARQL queries, the negative statements are exactly the complement of the statements listed in the RDF graphs in the dataset, so the behavior is also the same here. If, however, a negatively matched statement pattern does not match a negative statement (the matched statement is unknown), a result with skolem values is obtained. This result then is filtered out, because of the bound negation used in the query. Using standard negation as failure here as in [4], would let the bound negation succeed.
The extended SPARQL evaluation function defined above is used to define the direct consequence operator of the well founded semantics for true statements. For negative statements the direct consequence is defined using the negation of the greatest unfounded set.
We say dataset ![]() is
an unfounded set of
is
an unfounded set of ![]() ,
if for every polarized statement
,
if for every polarized statement ![]() in
any graph
in
any graph ![]() in
in ![]() the following hold:
the following hold:
![]() is positive and for every view
is positive and for every view
![]() in
in ![]() and for every complete solution mapping
and for every complete solution mapping ![]() for
for ![]() ,
such that
,
such that ![]() is in the CONSTRUCT pattern of
is in the CONSTRUCT pattern of
![]() , one of the following holds:
, one of the following holds:
The greatest unfounded set of ![]() is the union of all unfounded sets of
is the union of all unfounded sets of
![]() .
.
The second and third case make sure we treat solutions
correctly, which in principle meet the unfoundedness conditions
but are filtered out by some filter condition, which is not used
to define bound negation. We define the direct consequence
operator ![]() of the well founded semantics for NGs based
on unfounded sets and the evaluation function eval.
of the well founded semantics for NGs based
on unfounded sets and the evaluation function eval. ![]() assumes all statements in the greatest unfounded set to be
negative and thus introduces negative statements to NGs
evaluation.
assumes all statements in the greatest unfounded set to be
negative and thus introduces negative statements to NGs
evaluation.
Proof: directly from the definitions.
From theorem 4 follows, that
![]() has a fixpoint [20].
has a fixpoint [20].
For the finite case, the least fixpoint is reached in finitely many steps [20]. As NG definitions are finite, the only source of non finiteness can be blank nodes created in the CONSTRUCT patterns of view definitions. All other generated statements can only be made of elements of the finite set of RDF resources used in statements in the DISet. Hence, finiteness of NG evaluation can be checked using a simple syntactic test.