1. INTRODUCTION
Recent research on document retrieval has shown that there are several types of queries on the World Wide Web and that the ideal retrieval methods differ fundamentally depending on the query type.
Broder [3] classified queries on the Web into the following three types.
- navigational: the immediate intent is to reach a particular site
- informational: the intent is to acquire information assumed to be present on one or more Web pages
- transactional: the intent is to perform a Web-mediated activity
Existing test collections for Web retrieval, such as those produced for TREC and NTCIR, target the navigational and informational query types. Experimental results obtained with these test collections showed that the content of Web pages is useful for informational queries, whereas link or anchor information among Web pages is useful for navigational queries [5,9,14]. Li et al. [13] proposed a rule-based template-matching method to improve retrieval accuracy for transactional queries. Thus, classifying queries on the Web is crucial to selecting the appropriate retrieval method.
We propose methods to enhance Web retrieval and show their effectiveness experimentally. Our purpose is twofold. First, we propose a method to model anchor text for navigational queries. Compared with content-based retrieval, which has been studied for a long time, anchor-based retrieval has not been fully explored. Second, we propose a method to identify query types and use different retrieval methods depending on the query type. We target the navigational and informational query types because existing test collections do not target transactional queries.
Section 2 outlines our system for Web retrieval. Sections 3 and 4 elaborate on our anchor-based retrieval model and our method for classifying queries, respectively. Section 5 evaluates our methods and entire system experimentally.
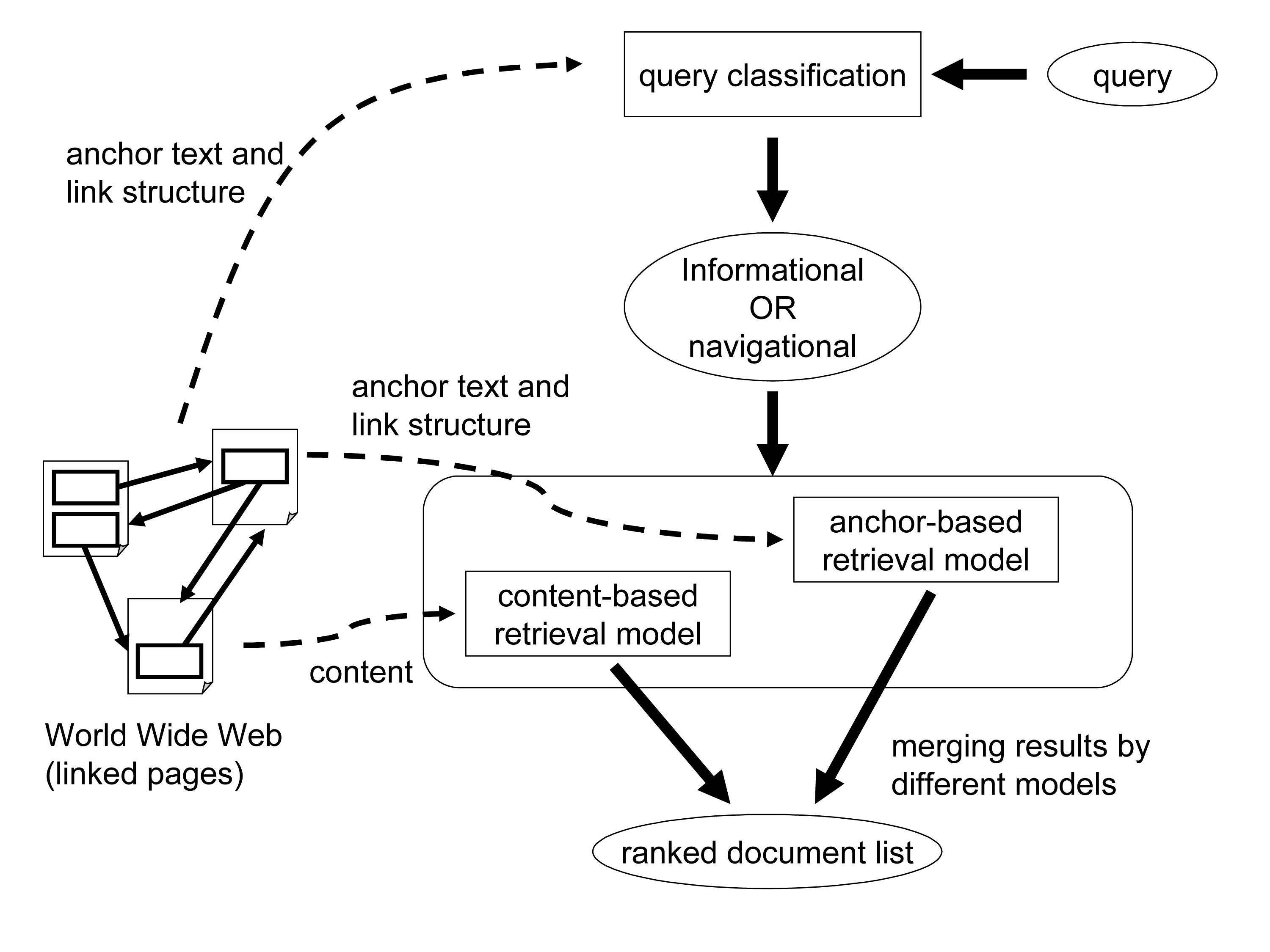
2. SYSTEM OVERVIEW
Figure 1 shows the overall design of our Web retrieval system, which consists of three modules: ``query classification'', ``content-based retrieval model'', and ``anchor-based retrieval model''.
The purpose of our system is to produce a ranked document list in response to a query. We target informational and navigational queries.
For informational queries, the purpose is the same as in conventional ad-hoc retrieval. For navigational queries, a user knows a specific item (e.g., a product, company, or person) and the purpose is to find one or more representative Web pages related to the item.
Irrespective of the query type, we always use both the content-based and anchor-based retrieval models. However, we change the weight of each model depending on the query type.
For preprocessing, we perform indexing for information on the Web. In content-based retrieval, index terms are extracted from the content of Web pages. In anchor-based retrieval, the anchor text and link structure on the Web are used for indexing purposes. We also use the anchor text and link structure to produce a query classifier.
We use the term ``link'' to refer to a hyperlink between two
Web pages and the term ``anchor text'' to refer to a clickable
string in a Web page used to move to another page. The following
example is a fragment of a Web page that links to
http://www.acm.org/. Here, ``ACM Site'' is anchor
text.
<A HREF="http://www.acm.org/">ACM Site</A>
Given a query, we first perform query classification to categorize the query as informational or navigational. We then use both the content-based and anchor-based retrieval models to produce two ranked document lists, in each of which documents are sorted according to the score with respect to the query. Finally, we merge the two ranked document lists to produce a single list.
Because the scores computed by the two retrieval models can
potentially have different interpretations and ranges, it is
difficult to combine them in a mathematically sound way. Thus, we
rerank each document by a weighted harmonic mean of the ranks in
the two lists. We compute the final score for document
![]() ,
, ![]() , as
follows.
, as
follows.
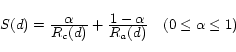
For the three modules in Figure 1, we use an existing model for content-based retrieval, but propose new methods for anchor-based retrieval (Section 3) and query classification (Section 4).
For the content-based retrieval, we index the documents in the Web collection by words and bi-words. We remove HTML tags from the documents and use ChaSen1 to perform morphological analysis and extract nouns, verbs, adjectives, out-of-dictionary words, and symbols as index terms. We use Okapi BM25 [16] to compute the content-based score for each document with respect to a query.
We also perform pseudo-relevance feedback, for which we collect the top 10 documents in the initial retrieval and use the top 10 terms to expand the original query. The ranks of the terms are determined by the weight of each term.
3. ANCHOR-BASED RETRIEVAL MODEL
3.1 Overview
A number of methods have been proposed to use links and anchor text in Web retrieval.
Yang [19] combined content-based and link-based retrieval methods. To use link information for retrieval purposes, Yang used an extension of the HITS algorithm [11], which determines hubs and authoritative pages using a link structure on the Web. However, Yang did not use anchor text for retrieval purposes.
Craswell et al. [4] used anchor text as surrogate documents and used Okapi BM25, which is a content-based retrieval model, to index the surrogate documents, instead of the content of the target pages.
Westerveld et al. [18] also used anchor text as
surrogate documents. However, because their retrieval method was
based on a language model, they used the surrogate documents to
estimate the probability of term ![]() given
surrogate document
given
surrogate document ![]() ,
, ![]() .
.
In Sections 3.2-3.4, we explain our anchor-based retrieval model. In Section 5.2, we compare the effectiveness of existing models and our model.
3.2 Entire Model
To use anchor text for retrieval purposes, we index the anchor
text in a Web collection by words and compute the score for each
document with respect to a query. We compute the probability that
document ![]() is the representative page for
the item expressed by query
is the representative page for
the item expressed by query ![]() ,
,
![]() . The task is to select
the
. The task is to select
the ![]() that maximizes
that maximizes ![]() , which is transformed using Bayes' theorem as
follows.
, which is transformed using Bayes' theorem as
follows.
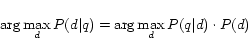
To extract term
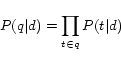
We extract anchor text from documents in the Web collection. However, because pages in the same Web server are often maintained by the same person or the same group of people, links and anchor texts between those pages can potentially be manipulated so that their pages can be retrieved in response to various queries. To resolve this problem, we discard the anchor text used to link to pages in the same server. Because we use a string matching method to identify servers, variants of the name of a single server, such as alias names, are considered different names. Additionally, even if a page links to another page more than once, we use only the first anchor text.
Because anchor texts are usually shorter than documents, the
mismatch between a term in an anchor text and a term in a query
potentially decreases the recall of the anchor-based retrieval. A
query expansion method is effective in resolving this problem.
However, for navigational queries, the precision is usually more
important than the recall. Thus, we expand a query term only if
![]() is not modeled in our
system. In such a case, we use a synonym of
is not modeled in our
system. In such a case, we use a synonym of ![]() ,
, ![]() , as a substitution of
, as a substitution of
![]() and approximate
and approximate ![]() as follows.
as follows.
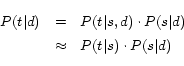
However, if no synonyms of ![]() are modeled
in our system, a different smoothing method is necessary;
otherwise the product calculated by Equation (3) becomes zero. For smoothing purposes, we
replace
are modeled
in our system, a different smoothing method is necessary;
otherwise the product calculated by Equation (3) becomes zero. For smoothing purposes, we
replace ![]() with
with ![]() , which is the probability that a term randomly
selected from the anchor texts in the Web collection is
, which is the probability that a term randomly
selected from the anchor texts in the Web collection is
![]() . Thus, if mismatched query terms
are general words that frequently appear in the collection, such
as ``system'' and ``page'', the decrease of
. Thus, if mismatched query terms
are general words that frequently appear in the collection, such
as ``system'' and ``page'', the decrease of ![]() in Equation (3) is
small. However, if mismatched query terms are low-frequency
words, which are usually effective for retrieval purposes,
in Equation (3) is
small. However, if mismatched query terms are low-frequency
words, which are usually effective for retrieval purposes,
![]() decreases
substantially.
decreases
substantially.
3.3 Modeling Anchor Text
To compute ![]() in Equation
(3), we use two alternative models.
in Equation
(3), we use two alternative models.
In the first model, taken from Westerveld et al. [18], the set of all anchor
texts linking to ![]() ,
, ![]() , is used as a single document,
, is used as a single document, ![]() , which is used as the surrogate content of
, which is used as the surrogate content of ![]() .
. ![]() is computed as
the ratio of the frequency of
is computed as
the ratio of the frequency of ![]() in
in
![]() to the total frequency of all terms
in
to the total frequency of all terms
in ![]() . We call this the ``document
model''.
. We call this the ``document
model''.
In the second model, which is proposed in this paper, each
anchor text ![]() is used
independently and
is used
independently and ![]() is
computed as follows.
is
computed as follows.
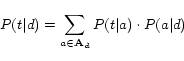
We illustrate the difference between these two models by
comparing the following two cases. In the first case, ![]() is linked from four anchor texts
is linked from four anchor texts ![]() ,
, ![]() ,
, ![]() ,
and
,
and ![]() . Each
. Each ![]() consists of a single term
consists of a single term ![]() . In the
second case,
. In the
second case, ![]() is linked from two anchor
texts
is linked from two anchor
texts ![]() and
and ![]() .
While
.
While ![]() consists of
consists of ![]() ,
, ![]() , and
, and ![]() ,
, ![]() consists of
consists of ![]() .
.
In the document model, ![]() is
is ![]() for each
for each ![]() in either case. However, this calculation is
counterintuitive. While in the first case each
in either case. However, this calculation is
counterintuitive. While in the first case each ![]() is equally important, in the second case
is equally important, in the second case ![]() should be more important than the other terms,
because
should be more important than the other terms,
because ![]() is equally as informative as
the set of
is equally as informative as
the set of ![]() ,
, ![]() ,
and
,
and ![]() . In the anchor model, while
. In the anchor model, while
![]() is 1,
is 1,
![]() is
is
![]() for the second case.
Thus, according to Equation (5), if
for the second case.
Thus, according to Equation (5), if
![]() and
and ![]() are equal,
are equal, ![]() becomes greater than
becomes greater than
![]() .
.
We further illustrate the difference between these two models
with a hypothetical example. We use the top page of ``Yahoo!
Japan'' (http://www.yahoo.co.jp/) as ![]() and
assume that
and
assume that ![]() is linked from the following
three anchor texts.
is linked from the following
three anchor texts.
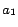 = {Yahoo, Japan}
= {Yahoo, Japan}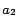 = {yafuu}
= {yafuu}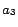 = {Yahoo}
= {Yahoo}
In the document model, ![]() for each term is as follows.
for each term is as follows.
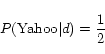
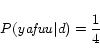
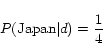
In the anchor model, ![]() for each term is calculated as follows.
for each term is calculated as follows.
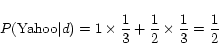
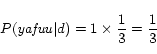
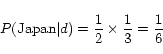
The difference of these two models is also associated with
spam. In the document model, the distribution of ![]() s in
s in ![]() is biased by a
large anchor text linking to
is biased by a
large anchor text linking to ![]() and
consequently the computation of
and
consequently the computation of ![]() can be manipulated by an individual or a small
group of people. In other words, the document model is vulnerable
to spam.
can be manipulated by an individual or a small
group of people. In other words, the document model is vulnerable
to spam.
However, the anchor model, which computes ![]() on an anchor-by-anchor basis, is robust
against spam. In Equation (5),
on an anchor-by-anchor basis, is robust
against spam. In Equation (5),
![]() becomes large when
becomes large when
![]() frequently appears in
frequently appears in ![]() and
and ![]() frequently links to
frequently links to
![]() . If many people use
. If many people use ![]() to link to
to link to ![]() ,
, ![]() becomes large, but it is difficult for an
individual to manipulate
becomes large, but it is difficult for an
individual to manipulate ![]() .
If an individual produces
.
If an individual produces ![]() that rarely
links to
that rarely
links to ![]() , he/she can manipulate
, he/she can manipulate
![]() , but
, but ![]() becomes small.
becomes small.
In summary, the anchor model is robust against spam and more intuitive than the document model. We compare the effectiveness of these two models quantitatively in Section 5.2.
3.4 Extracting Synonyms
When multiple anchor texts link to the same Web page, they generally represent the same or similar content. For example, ``google search'' and ``guuguru kensaku'' (romanized Japanese translation corresponding to ``google search'') can independently be used as anchor texts to produce a link to ``http://www.google.co.jp/''.
While existing methods to extract translations use documents as a bilingual corpus [17], we use a set of anchor texts linking to the same page as a bilingual corpus. Because anchor texts are short, the search space is limited and thus the accuracy may be higher than that for general translation extraction tasks.
In principle, both translations and synonyms can be extracted by our method. However, in practice we target only transliteration equivalents, which can usually be extracted with high accuracy, relying on phonetic similarity. We target words in European languages (mostly English) and their translations spelled out with Japanese Katakana characters.
Our method consists of the following three steps.
- identification of candidate word pairs
- extraction of transliteration equivalents
- computation of
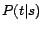 that
will be used in Equation (4)
that
will be used in Equation (4)
In the first step, we identify words written with the Roman alphabet or the Katakana alphabet. These words can be identified systematically in the EUC-JP character code.
In the second step, for any pair of European word ![]() and Japanese Katakana word
and Japanese Katakana word ![]() , we examine whether or not
, we examine whether or not ![]() is a
transliteration of
is a
transliteration of ![]() . For this purpose,
we use a transliteration method [7]. If either
. For this purpose,
we use a transliteration method [7]. If either ![]() or
or ![]() can be transliterated into its
counterpart, we extract (
can be transliterated into its
counterpart, we extract (![]() ,
,![]() ) as a transliteration-equivalent pair. We compute
the probability that
) as a transliteration-equivalent pair. We compute
the probability that ![]() is a transliteration
of
is a transliteration
of ![]() ,
, ![]() ,
and select the
,
and select the ![]() that maximizes
that maximizes ![]() , which is transformed as follows using
Bayes' theorem.
, which is transformed as follows using
Bayes' theorem.
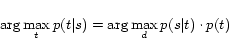
We extract (![]() ,
,![]() ) as a
transliteration equivalent pair only if
) as a
transliteration equivalent pair only if ![]() or
or ![]() takes a
positive value. Because transliteration is not an invertible
operation, we compute both
takes a
positive value. Because transliteration is not an invertible
operation, we compute both ![]() and
and ![]() to increase the recall of
the synonym extraction.
to increase the recall of
the synonym extraction.
We do not use ![]() as
as
![]() in Equation (4), because we require the probability that
in Equation (4), because we require the probability that
![]() can substitute for
can substitute for ![]() when used in an anchor text. Thus, Equation (6) is used only for extracting transliteration
equivalents.
when used in an anchor text. Thus, Equation (6) is used only for extracting transliteration
equivalents.
In the final step, we compute ![]() as follows.
as follows.
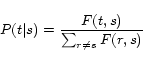
4. QUERY CLASSIFICATION
4.1 Overview
The purpose of query classification is to categorize queries into the informational and navigational types. A number of methods have been proposed [1,9,12].
Kang and Kim [9] used multiple features for query classification purposes and demonstrated their effectiveness using the TREC WT10g collection. Search topics for the topic relevance and homepage finding tasks were used as informational and navigational queries, respectively.
Lee et al. [12] performed human subject studies and showed that user-click behavior and anchor-link distribution are effective for query classification purposes. They also argued that the features proposed by Kang and Kim are not effective for query classification purposes. However, because they did not perform Web retrieval experiments, the effects of their query classification method on retrieval accuracy are not clear.
In this paper, we enhance the classification method proposed by Lee et al.and show its effectiveness in Web retrieval. However, we do not use user-click behaviors because we do not have search log information. We use only the anchor-link distribution, which can be collected from the anchor texts and link information in a Web collection. Thus, unlike a log-based query classification method [1], our method does not require large amounts of search log information.
In Section 5.3, we compare the effectiveness of our classification method and existing methods.
4.2 Methodology
The idea of the use of the anchor-link distribution proposed by Lee et al. [12] is as follows. For a navigational query, a small number of authoritative pages usually exist. Thus, the anchor text that is the same as the query is usually used to link to a small number of pages. However, for an informational query, the anchor text that is the same as the query, if it exists, is usually used to link to a large number of pages.
Given a query, Lee et al. computed its anchor-link
distribution as follows. First, they located all the anchors
appearing on the Web that had the same text as the query, and
extracted their destination URLs. Then, they counted how many
times each destination URL appeared in this list and sorted the
destinations in the descending order of their appearance. They
created a histogram in which the frequency count in the
![]() th bin was the number of times that
the
th bin was the number of times that
the ![]() th destination appeared. Finally,
they normalized the frequency in each bin so that the frequency
values summed to one.
Figure 2 shows example histograms
produced by this method, in which (a) and (b) usually correspond
to histograms for navigational and informational queries,
respectively. While the distribution in (a) is skewed, the
distribution in (b) is uniform.
th destination appeared. Finally,
they normalized the frequency in each bin so that the frequency
values summed to one.
Figure 2 shows example histograms
produced by this method, in which (a) and (b) usually correspond
to histograms for navigational and informational queries,
respectively. While the distribution in (a) is skewed, the
distribution in (b) is uniform.
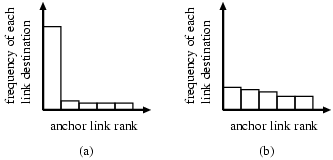
To distinguish the two histograms depicted by Figures 2 (a) and (b), Lee et al. computed how skewed the distribution was, for which several standard statistical measures were used.
However, Lee et al. considered only anchor texts that were exactly the same as the given query. Thus, if a given query consisted of more than one term, such as ``information retrieval'' and ``trec, nist, test collection'', and there was no anchor text exactly the same as this query, the anchor-link distribution for this query could not be computed. This limitation is also problematic for queries consisting of a single term, if a query is in an agglutinative language, in which multiple query terms are combined without lexical segmentation.
To resolve this problem, we modify Lee et al.'s method. In brief, if a query does not appear in the anchor texts in the Web collection as it is, we decompose the query into terms and compute the anchor-link distribution for each term.
We consider a set of terms in query ![]() ,
,
![]() . We also consider a set
of documents linked by the anchor texts including
. We also consider a set
of documents linked by the anchor texts including
![]() ,
, ![]() . We use ChaSen to extract terms
. We use ChaSen to extract terms ![]() from query
from query ![]() . To quantify the
degree to which the anchor-link distribution for
. To quantify the
degree to which the anchor-link distribution for ![]() is skewed, unlike Lee et al.'s method, we compute the
conditional entropy of
is skewed, unlike Lee et al.'s method, we compute the
conditional entropy of ![]() given
given
![]() ,
,
![]() as
follows.
as
follows.
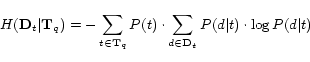
![]() denotes the probability with
which term
denotes the probability with
which term ![]() appears in query
appears in query ![]() . Because queries are usually short, we use the
uniform distribution of
. Because queries are usually short, we use the
uniform distribution of ![]() and thus
and thus
![]() .
.
![]() denotes the probability
that document
denotes the probability
that document ![]() is linked by the anchor
texts including term
is linked by the anchor
texts including term ![]() .
. ![]() is the length of the bin including
is the length of the bin including ![]() in the histogram produced by Lee's method. In Figure
2, each bin denotes the frequency of
destination documents linked by a specific anchor text, divided
by the total frequency of all documents in the histogram.
While Lee et al. assumed that
in the histogram produced by Lee's method. In Figure
2, each bin denotes the frequency of
destination documents linked by a specific anchor text, divided
by the total frequency of all documents in the histogram.
While Lee et al. assumed that ![]() and
and
![]() were identical and considered only
the distribution of
were identical and considered only
the distribution of ![]() , we assume
that
, we assume
that ![]() consists of more than one term and
consider a combination of
consists of more than one term and
consider a combination of ![]() for different
for different ![]() s.
s.
Using
![]() , we
compute the degree to which query
, we
compute the degree to which query ![]() should be regarded as an informational query,
should be regarded as an informational query, ![]() . We divide
. We divide
![]() by
by
![]() , so that
the range of the value of
, so that
the range of the value of ![]() is
is
![]() .
.
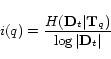
We have two alternative methods for using ![]() . First, we use
. First, we use ![]() only to
determine the query type. The value of
only to
determine the query type. The value of ![]() in Equation (1) is
determined independently. Second, we use
in Equation (1) is
determined independently. Second, we use ![]() as
as ![]() in Equation (1), so that we can determine the value of
in Equation (1), so that we can determine the value of
![]() automatically. In Section
5, we compare the effectiveness of these
methods.
automatically. In Section
5, we compare the effectiveness of these
methods.
We can further enhance our classification method. If term
![]() is not included in the anchor texts
on the Web, we use a synonym of
is not included in the anchor texts
on the Web, we use a synonym of ![]() to compute
to compute
![]() . To extract a synonym of a term,
we use the method proposed in Section 3.4. However, we simply replace
. To extract a synonym of a term,
we use the method proposed in Section 3.4. However, we simply replace ![]() with
with ![]() and do not use
and do not use
![]() in the computation of
in the computation of
![]() .
.
In summary, we have resolved three issues that were not addressed in Lee et al. [12]. First, our method can compute the anchor-link distribution of queries for which the query text does not exist as anchor text on the Web. Second, our method can determine the weight of the content-based and anchor-based retrieval methods automatically. Finally, our method can use synonyms of query terms for smoothing purposes.
Our method is associated with two parametric constants.
![]() can potentially be small, if few
of terms in
can potentially be small, if few
of terms in ![]() are used in the anchor texts on
the Web. In such a case,
are used in the anchor texts on
the Web. In such a case, ![]() is regarded
as a navigational query irrespective of the informational need
behind
is regarded
as a navigational query irrespective of the informational need
behind ![]() . To avoid this problem, if term
. To avoid this problem, if term
![]() is not used in the anchor texts, we
estimate the frequency of documents linked by anchor text
including
is not used in the anchor texts, we
estimate the frequency of documents linked by anchor text
including ![]() by a default value. We
empirically set this parameter to 10 000.
The other parameter is the bin size in the histogram as in Figure
2. We empirically set this parameter
to 5. The values of these parameters should be determined by the
size of a target Web collection. We have not identified an
automatic method to determine the optimal values. However, this
issue is also related to Lee's method.
by a default value. We
empirically set this parameter to 10 000.
The other parameter is the bin size in the histogram as in Figure
2. We empirically set this parameter
to 5. The values of these parameters should be determined by the
size of a target Web collection. We have not identified an
automatic method to determine the optimal values. However, this
issue is also related to Lee's method.
5. EVALUATION
5.1 Evaluation Method
We evaluated the effectiveness of our proposed methods with three experiments. First, we evaluated the effectiveness of the anchor-based retrieval model proposed in Section 3. Second, we evaluated the effectiveness of the query classification method proposed in Section 4. Finally, we evaluated the accuracy of our Web retrieval system as a whole, proposed in Section 2.
Table 1 shows a summary of the test collections used for our experiments. We use the test collections produced for NTCIR-3 [6] and NTCIR-4 [5,14]. These share a target document set, which consists of 11 038 720 pages collected from the JP domain. Thus, most of the pages are in Japanese. The file size is approximately 100 GB, which is 10 times the size of the TREC WT10g collection.
Table 1: Test collections used for experiments.
| NTCIR-3 | NTCIR-4 | NTCIR-5 | ||
| Topic type (#Topics) | info (47) | info (80) | navi (168) | navi (841) |
| Doc size | 100 GB | 1 TB | ||
| Avg#Rels | 75.7 | 84.5 | 1.79 | 1.94 |
| Avg#Terms | 2.89 | 2.39 | 1.39 | 1.35 |
| Experiments | Sections 5.3, 5.4, 5.5 | |||
| Section 5.2 | ||||
We also used the test collection produced for NTCIR-5 [15]. The target document set for NTCIR-5 consists of 95 870 352 pages collected from the JP domain. The file size is approximately 1 TB, which is 10 times the size of the NTCIR-3/4 collection.
Search topics are also in Japanese. While the NTCIR-3 collection includes only informational search topics, the NTCIR-4 collection includes both informational and navigational search topics. Because these topics target the same document collection, we can use them to evaluate our query classification. However, because the NTCIR-5 collection includes only navigational search topics, we use these topics to evaluate the anchor-based retrieval model.
In the relevance judgment, the relevance of each document with respect to a topic was judged as ``highly relevant'', ``relevant'', ``partially relevant'', or ``irrelevant''. We used only topics for which at least one highly relevant or relevant document was found. As a result, we collected 47 topics from the NTCIR-3 collection and 80 informational topics and 168 navigational topics from the NTCIR-4 collection, respectively, and a further 841 topics from the NTCIR-5 collection. Thus, we used 1009 (168 + 841) topics for the evaluation of the anchor-based retrieval model, and 127 (47 + 80) informational topics and 168 navigational topics for the evaluation of the query classification.
We used the highly relevant and relevant documents as the correct answers. The average numbers of correct answers were 75.7 for the NTCIR-3 information topics, 84.5 for the NTCIR-4 informational topics, 1.79 for the NTCIR-4 navigational topics, and 1.94 for the NTCIR-5 navigational topics, respectively.
For each topic, we used only the terms in the ``TITLE'' field, which consists of one or more terms, as a query. The average numbers of terms were 2.89 for the NTCIR-3 information topics, 2.39 for the NTCIR-4 informational topics, 1.39 for the NTCIR-4 navigational topics, and 1.35 for the NTCIR-5 navigational topics, respectively.
In Section 5.2, we evaluate the anchor-based retrieval methods, for which we used only the navigational queries in the NTCIR-4 and NTCIR-5 collections. In this evaluation, we used Mean Reciprocal Rank (MRR) as the evaluation measure. MRR has commonly been used to evaluate precision-oriented retrieval, such as retrievals for navigational queries and question answering. For each query, we calculated the reciprocal of the rank at which the first correct answer was found in the top 10 documents. MRR is the mean of the reciprocal ranks for all queries.
In Section 5.3, we evaluate the accuracy of query classification methods, for which we used both the informational and navigational queries in the NTCIR-3 and NTCIR-4 collections. We also evaluate the contribution of each query classification method to the retrieval accuracy. We used Mean Average Precision (MAP) and MRR as the evaluation measures of the retrieval accuracy. MAP, which considers both precision and recall, is appropriate to evaluate the retrieval for the informational queries. To calculate MAP, we used the top 100 documents.
In Section 5.4, we analyze the errors of our query classification method and their effects on the retrieval accuracy, for which we used the NTCIR-3 and NTCIR-4 collections.
In Section 5.5, we evaluate our system as a whole. We used the NTCIR-3 and NTCIR-4 collections and evaluated a combination of the methods proposed in this paper.
5.2 Evaluating the Anchor-based Retrieval Model
Using the 168 navigational queries in NTCIR-4 and the 841 navigational queries in NTCIR-5, we compared the MRR of the following retrieval methods.
- CC: a content-based retrieval model that uses Okapi BM25 to index the content of the target pages (Section 2)
- CS: a content-based retrieval model that uses anchor texts as surrogate documents and uses Okapi BM25 to index them [4]
- ADP: an anchor-based retrieval model (Section 3) that computes
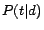 and
and 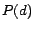 by
the document model [18] and PageRank,
respectively
by
the document model [18] and PageRank,
respectively - ADM: the same as ADP but computes by the maximum likelihood estimation
- AAP: an anchor-based retrieval model that computes
and by the anchor model proposed in Section 3.3 and PageRank, respectively
- AAM: the same as AAP but computes by the maximum likelihood estimation
- AAMS: a combination of AAM and the synonym-based smoothing proposed in Section 3.4
- AAMSC: a combination of CC and AAMS according to Equation (1)
Comparison of CC and CS, which used the same retrieval model but indexed different information, shows that the use of the anchor text was effective in substantially improving MRR.
Comparison of CS and each of the anchor-based model variations ADP, ADM, AAP, AAM, AAMS, and AAMSC, which used the same information but used different models, shows that the method of modeling anchor text was crucial. For navigational queries, our anchor-based retrieval model was more effective than Okapi BM25, irrespective of the implementation variation.
Comparison of ADP and ADM (or AAP and AAM), which used the
same retrieval model but different implementations for
![]() , shows that maximum likelihood
estimation was more effective than PageRank in the computation of
, shows that maximum likelihood
estimation was more effective than PageRank in the computation of
![]() .
.
Comparison of ADP and AAP (or ADM and AAM), which used the
same retrieval model but used different implementations for
![]() , shows that the anchor
model proposed in this paper was more effective than an existing
method [18].
, shows that the anchor
model proposed in this paper was more effective than an existing
method [18].
Comparison of AAM and AAMS shows that synonym-based smoothing was effective in improving MRR in NTCIR-4. Through a topic-by-topic analysis, we found that the improvement was caused by topic #0064, for which an English translation of the query is ``The Princeton Review of Japan''2. For this query, the reciprocal rank was 0 without smoothing. However, the reciprocal rank was 1 with smoothing.
Comparison of AAMS and AAMSC shows that combining the
anchor-based and content-based retrieval models was effective in
improving MRR in NTCIR-4, but not in NTCIR-5. The optimal value
of ![]() was determined by preliminary
experiments. We set
was determined by preliminary
experiments. We set ![]() and
and
![]() for NTCIR-4 and NTCIR-5,
respectively.
for NTCIR-4 and NTCIR-5,
respectively.
Table 2: MRR of retrieval methods for navigational queries.
| Method | NTCIR-4 | NTCIR-5 |
| CC | 0.063 | 0.047 |
| CS | 0.458 | 0.446 |
| ADP | 0.556 | 0.556 |
| ADM | 0.590 | 0.675 |
| AAP | 0.567 | 0.577 |
| AAM | 0.606 | 0.691 |
| AAMS | 0.612 | 0.691 |
| AAMSC | 0.618 | 0.691 |
In summary, a) the anchor text model, b) the smoothing method using automatically extracted synonyms, and c) a combination of the anchor-based and content-based retrieval models were independently effective in improving the accuracy of navigational Web retrieval.
Because the above items a) and b) were proposed in this paper, our contribution improved MRR from 0.590 (ADM) to 0.606 (AAM) and 0.612 (AAMS) for NTCIR-4, and from 0.675 (ADM) to 0.691 (AAM/AAMS) for NTCIR-5. We used the paired t-test for statistical testing, which investigates whether the difference in performance is meaningful or simply because of chance [8,10]. The differences of ADM and AAM for NTCIR-4 and NTCIR-5 were significant at the 5% and 1% levels, respectively. However, the differences between AAM and AAMS were not significant for NTCIR-4 and NTCIR-5. We can conclude that the anchor text model was effective in improving the accuracy of navigational Web retrieval.
5.3 Evaluating Query Classification
Using the 127 informational queries and the 168 navigational queries in NTCIR-3 and NTCIR-4, we evaluated the effectiveness of our query classification method.
As comparisons, we used the query classification methods proposed by Kang and Kim [9] and Lee et al. [12]. Kang's method used four features: distribution of query terms, mutual information, usage rate as an anchor text, and part-of-speech information. Kang and Kim integrated the four features by a linear combination, for which the optimal weights of each feature were determined manually. However, because manual optimization of different weights was prohibitive, we evaluated each feature independently.
We did not use the part-of-speech feature. Because the TREC queries used by Kang and Kim included natural language phrases, verbs appear in informational queries more often than in navigational queries. However, because the NTCIR queries consist of only nouns, it is obvious that the part-of-speech feature is not effective for query classification purposes.
For each of the remaining three features, we implemented a query classifier. Each classifier computes the score of a given query and determines the query type by comparing the score and a predetermined threshold. Because the threshold of each classifier must be determined manually, we evaluated each classifier using different values of the threshold and selected the optimal value.
Kang and Kim used two threshold values and did not identify the query type if the score fell between the two threshold values. This method is effective in improving accuracy, although it decreases coverage. However, because manual optimization of different threshold values was prohibitive, we used a single threshold for each classifier.
First, we compared the following methods in terms of the accuracy of query classification.
- DI: the distribution of query terms feature in Kang and Kim's method
- MI: the mutual information feature in Kang and Kim's method
- AN: the usage rate of anchor text in Kang and Kim's method
- LM: Lee's method
- OM: our method
Table 3 shows the accuracy of different query classification methods. It is apparent that in Kang and Kim's method, the accuracy of AN was greatest. The accuracy of OM was greater than those of the other methods. Thus, our query classification method was more effective than these existing methods.
Table 3: Accuracy of query classification methods.
| Method | Accuracy |
| DI | 53.9 |
| MI | 43.1 |
| AN | 75.6 |
| LM | 72.5 |
| OM | 79.3 |
We analyzed the effect of synonym-based expansion and found that the following two queries, which are both navigational queries in the NTCIR-4 collection, were correctly classified by the synonym-based expansion: #0010 ``SHARP, liquid crystal TV'' and #0078 ``France, sightseeing''.
Second, we compared the following methods in terms of the accuracy of Web retrieval.
- NC: no query classification, with
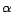 in Equation (1)
always 0.5 irrespective of the query type
in Equation (1)
always 0.5 irrespective of the query type - AN: the usage rate of anchor text in Kang and Kim's method
- LM: Lee's method
- O1: our method, with
predefined
- O2: our method, with
determined automatically by Equation (9)
- CT: correct query type defined in the NTCIR-3/4 collections
Each method used CC and AAMS in Section 5.2 for the content-based and anchor-based retrieval models, respectively. Thus, the MAP and MRR of each method were determined only by the query classification accuracy.
Because Kang and Kim did not compare their method with the case of no classification (NC), our experiment is the first effort to evaluate the contribution of query classification to Web retrieval accuracy.
Table 4 shows the MAP and MRR for the different retrieval methods. Although CT outperformed the other methods in MAP and MRR, our methods (O1 and O2) outperformed NC, AN, and LM in MAP and MRR. Thus, our query classification method was more effective in improving Web retrieval accuracy than the existing automatic classification methods.
In the existing classification methods, AN outperformed NC and LM. We used the paired t-test for statistical testing and found that the difference between AN and each of our methods (O1 and O2) was significant at the 5% level in MAP but was not significant in MRR. However, in Section 5.5 we show that a combination of our proposed methods improved the MAP and MRR of a baseline retrieval system significantly.
Table 4: MAP and MRR of retrieval methods for informational and navigational queries.
| Method | MAP | MRR |
| NC | 0.254 | 0.468 |
| AN | 0.281 | 0.504 |
| LM | 0.265 | 0.485 |
| O1 | 0.300 | 0.519 |
| O2 | 0.304 | 0.517 |
| CT | 0.312 | 0.545 |
5.4 Error Analysis for Query Classification
We analyzed the queries that were misclassified by our method (OM in Table 3). We also analyzed how the retrieval accuracy was changed by the errors, for which we compared O2 and CT in Table 4 with respect to AP (Average Precision) and RR (Reciprocal Rank). Note that MAP and MRR are evaluation measures for all queries and that for each query only AP and RR can be calculated.
We identified two error types for informational queries and
four error types for navigational queries. Table 5 shows the number of cases and changes of AP
and RR for each error type. In Table 5,
``![]() '', ``='', and
``
'', ``='', and
``![]() '' denote ``decrease'',
``equality'', and ``increase'' of AP/RR for O2 compared with
those for CT. Although AP and RR were usually decreased by
misclassified queries, for some queries AP or RR were increased
by the classification error.
'' denote ``decrease'',
``equality'', and ``increase'' of AP/RR for O2 compared with
those for CT. Although AP and RR were usually decreased by
misclassified queries, for some queries AP or RR were increased
by the classification error.
Table 5: Error types of query classification and changes of AP and RRa.
| AP | RR | |||||||
| Error type | Query type | #Errors | = | = | ||||
| (a) | info | 14 | 14 | 0 | 0 | 10 | 3 | 1 |
| (b) | info | 9 | 9 | 0 | 0 | 5 | 3 | 1 |
| (c) | navi | 27 | 8 | 9 | 10 | 6 | 16 | 5 |
| (d) | navi | 1 | 1 | 0 | 0 | 1 | 0 | 0 |
| (e) | navi | 4 | 0 | 4 | 0 | 0 | 4 | 0 |
| (f) | navi | 1 | 1 | 0 | 0 | 1 | 0 | 0 |
In the following, we elaborate on the error types (a)-(f). To exemplify queries, we use English translations of original Japanese queries. While errors (a)-(c) occurred because we decomposed a query into more than one term, errors (d)-(f) were common to query classification methods that use anchor texts on the Web.
Error (a)
As explained in Section 4.2, if there is no anchor text
that is the same as a query, we decompose the query into more
than one term. When these terms are used as independent anchor
texts, the entropy for each term is small and ![]() for this query is also small. An example query is
#0001 ``offside, football, rule'' in the NTCIR-4 collection.
for this query is also small. An example query is
#0001 ``offside, football, rule'' in the NTCIR-4 collection.
There were 14 queries misclassified for this reason. For 10 queries RR decreased and for three queries RR did not change. However, for one query, #0112 ``sauna, Finland'' in the NTCIR-4 collection, RR increased.
Error (b)
When all terms in a query appear in the same anchor text,
![]() for this query becomes small. An
example query is #0029 ``photoshop, tips'' in the NTCIR-4
collection.
for this query becomes small. An
example query is #0029 ``photoshop, tips'' in the NTCIR-4
collection.
There were nine queries misclassified for this reason. For five queries RR decreased and for three queries RR did not change. However, for one query, #0013 ``Kyoto, temple, shrine'' in the NTCIR-3 collection, RR increased from 0.33 to 1. In this example, although a user intended to submit an informational query, a representative page related to sightseeing for Kyoto was found by the anchor-based retrieval module.
Error (c)
Like error (a), this error occurs because we decompose the
query into more than one term. However, unlike error (a), because
these terms were general words that were frequently used in
different anchor texts, the entropy for each term was large and
![]() was also large.
was also large.
An example query is #0159 ``Venusline, sightseeing'' in the
NTCIR-4 collection. In this example, because ``Venusline'' is a
proper noun of a road, this term tends to be used as a
navigational query. However, the entropy of ``sightseeing'' was
so large that the entropy of ``Venusline'' was overshadowed. As a
result, ![]() for this query became
large.
for this query became
large.
Error (d)
When no terms in a query appear in the anchor texts in the Web
collection, ![]() for the query becomes large.
This case often happens when a query consists of an infrequent
proper noun, such as #0160 ``Ganryuu island'' in the
NTCIR-4 collection.
for the query becomes large.
This case often happens when a query consists of an infrequent
proper noun, such as #0160 ``Ganryuu island'' in the
NTCIR-4 collection.
Error (e)
Query #0092 ``genetically modified food'' appears in a number
of anchor texts in different contexts, such as ``The homepage of
genetically modified food at the Ministry of Health, Labour, and
Welfare'' and ``Frequently asked questions for genetically
modified food''. Therefore, the distribution of the destination
documents linked by these anchor texts was not skewed. As a
result, ![]() for this query became
large.
for this query became
large.
Error (f)
If the degree of skewness is not sufficient, ![]() becomes greater than 0.5. There was only a single
such query, #0192 ``Coca-Cola'', for which
becomes greater than 0.5. There was only a single
such query, #0192 ``Coca-Cola'', for which ![]() was 0.549.
was 0.549.
5.5 Evaluating the Entire Retrieval System
We evaluated the accuracy of our Web retrieval system as a whole. As shown in Figure 1, our system consists of three modules. For each module, a baseline system used the existing method that achieved the highest accuracy in our experiments: ADM in Table 2 for the anchor-based retrieval model and AN in Table 3 for the query classification. All systems used CC in Table 2 as the content-based retrieval model.
Table 6 shows the MAP and MRR of the different retrieval systems, in which BL denotes the results of the baseline system. The results for O1, O2, and CT are the same as those in Table 4. In Table 6, our systems (O1 and O2) outperformed the baseline system in both MAP and MRR.
Table 6: MAP and MRR of retrieval systems.
| System | MAP | MRR |
| BL | 0.272 | 0.491 |
| O1 | 0.300 | 0.519 |
| O2 | 0.304 | 0.517 |
| CT | 0.312 | 0.545 |
Table 7 shows the results of the
paired t-test for statistical testing, in which ``![]() '' and ``
'' and ``![]() '' indicate that
the difference of two results was significant at the 5% and 1%
levels, respectively, and ``--'' indicates that the difference of
two results was not significant. The difference between BL and O1
was statistically significant for MAP and MRR. The difference
between BL and O2 was also statistically significant for MAP and
MRR. The difference between CT and each of our systems (O1 and
O2) was not significant in MAP.
'' indicate that
the difference of two results was significant at the 5% and 1%
levels, respectively, and ``--'' indicates that the difference of
two results was not significant. The difference between BL and O1
was statistically significant for MAP and MRR. The difference
between BL and O2 was also statistically significant for MAP and
MRR. The difference between CT and each of our systems (O1 and
O2) was not significant in MAP.
In summary, irrespective of whether the value of ![]() is determined manually or automatically, our
system outperformed the baseline system significantly in MAP and
MRR. Thus, we can reduce the manual cost required to optimize the
value of
is determined manually or automatically, our
system outperformed the baseline system significantly in MAP and
MRR. Thus, we can reduce the manual cost required to optimize the
value of ![]() . In addition, our proposed
methods significantly improved the accuracy of Web document
retrieval.
. In addition, our proposed
methods significantly improved the accuracy of Web document
retrieval.
Table 7: t-test results for differences
between retrieval systems (``![]() '': 0.01, ``
'': 0.01, ``![]() '':
0.05, ``--'': not significantly different).
'':
0.05, ``--'': not significantly different).
| MAP | MRR | |
| BL vs. O1 | ||
| BL vs. O2 | ||
| O1 vs. CT | -- | |
| O2 vs. CT | -- |
6. CONCLUSION
There are several types of queries on the Web and the expected retrieval method can vary depending on the query type. We have proposed a Web retrieval system that consists of query classification, anchor-based retrieval, and content-based retrieval modules.
We have proposed a method to classify queries into the informational and navigational types. Because terms in navigational queries often appear in the anchor text of links to other pages, we analyzed the distribution of query terms in the anchor texts on the Web for query classification purposes. While content-based retrieval is effective for informational queries, anchor-based retrieval is effective for navigational queries. Our retrieval system combines the results obtained with the content-based and anchor-based retrieval methods, in which the weight for each retrieval result is determined automatically depending on the result of the query classification.
We have also proposed a method to model anchor text for anchor-based retrieval. Our retrieval method, which computes the probability that a document is retrieved in response to a given query, identifies synonyms of query terms in the anchor texts on the Web and uses these synonyms for smoothing purposes in the probability estimation.
We used the 100 GB and 1 TB Web collections produced in NTCIR workshops, and showed the effectiveness of individual methods and the entire Web retrieval system experimentally. Our anchor-based retrieval method improved the accuracy of existing methods. In addition, our entire system improved the accuracy of the baseline system. These improvements were statistically significant.
Although we targeted the informational and navigational queries, future work includes targeting other types of queries, such as transactional queries.
7. ACKNOWLEDGMENTS
The author would like to thank the organizers of the NTCIR WEB task for their support with the Web test collections. This research was supported in part by MEXT Grant-in-Aid Scientific Research on Priority Area of ``New IT Infrastructure for the Information-explosion Era'' (Grant No. 19024007).